Sign In / Sign Out
Navigation for Entire University
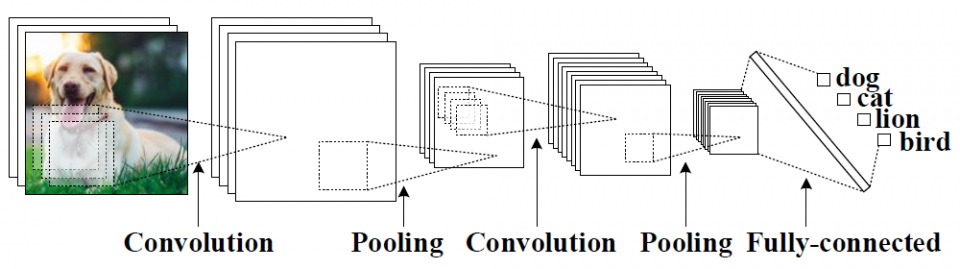
Convolutional neural network (CNN) has become a popular machine learning engine for many image-related data analytics [15-16] [20] [27], such as image classification, face detection, object tracking, etc. CNNs outperform traditional feature selection based approaches especially for learning from big data. For a conventional CNN, high computation complexity and large memory footprint are the two main throughput bottlenecks for hardware acceleration. Therefore, the unmet throughput need of CNNs calls for the development of more efficient hardware acceleration solutions for driving real-time applications.
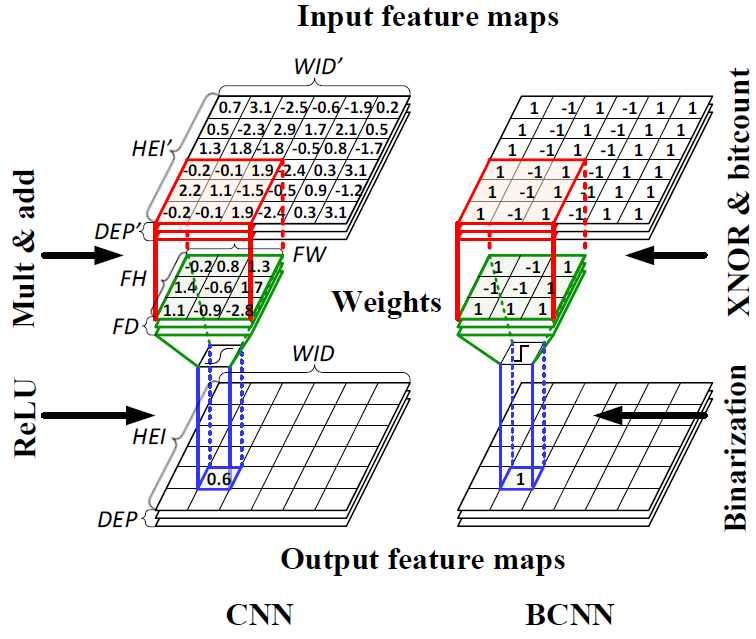
Several methods have been proposed to alleviate the computation complexity and memory footprint by reducing the redundancy of CNN models. These methods include pruning [18] [26], reduced-precision CNNs [4], and binary CNNs (BCNNs) [9]. The pruning technique [18] prunes the “useless” weights of a trained network based on sensitivity analysis, which can effectively reduce the CNN weight count (usually referred to as network size) for a ten-class classification problem by 75% [18]. Ref. 4 demonstrates that reducing the numerical precision of a CNN from 32 to 16 bits has very limited impact on classification accuracy. This can result in a network size reduction of 50%. However, a numerical precision below 8 bits resulted from quantization in the post-training stage often suffers from unacceptable accuracy drop [4]. Alternatively, recent advancement in binary-constrained deep learning has opened up new opportunities for efficient hardware acceleration. BinaryConnect [5] and the work in Ref. 6 demonstrate the successful use of binary and ternary (-1, 0, +1) weights in a CNN, respectively. But, they both have non-binary activations. As one step forward, EBP [7], Bitwise DNNs [8], and the BCNN in Ref. 9 successfully exploit both binary weights and activations. In particular, the BCNN in Ref. 9 shows a 0.96% classification error rate on the MNIST database [17], which is comparable to a full-precision state-of-the-art CNN. Overall, BCNNs have been shown with up to 96.8% reduced network sizes with minimum accuracy loss when comparing to their full-precision counterparts. Therefore, it is believed that BCNN is a more hardware-friendly model with superior accuracy-complexity trade-off.
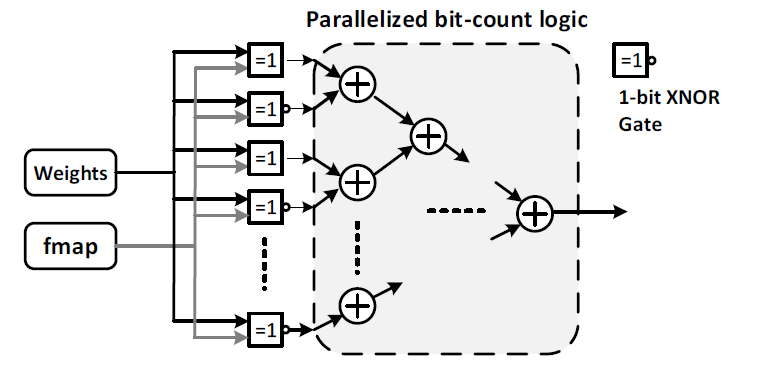
Thus far, GPU-based CNN accelerator is still dominant due to its improved throughput over CPUs. However, the high power consumption of GPUs has brought up cooling concerns in data center computing. On the other hand, FPGA-based CNN accelerator has been widely investigated due to its energy efficiency benefits. As the system throughput is proportional to the computing parallelism and operating frequency, the theoretical throughput of GPU-based and FPGA-based CNN accelerators can be estimated on the 1st order based on device specifications. A Titan X GPU has 3,072 CUDA cores, while a Virtex-7 FPGA has 3,600 DSP48 slices. For implementing a full-precision CNN, the computing parallelism of GPUs and FPGAs can be approximately the same. But, GPUs offer 5-10x higher frequency. As a result, FPGAs can hardly match up the throughput of GPUs for accelerating full-precision CNNs. Differently, for a BCNN, the operations in the convolution layers become bitwise XNORs and bit-count logic. A direct impact is that one can use LUTs instead of DSP48 slices to implement the bitwise operations on an FPGA. Hundreds of thousands of LUTs make it possible for a high-end FPGA to match up or surpass the throughput of a GPU, even considering the bitwise operation capability of CUDA cores. Moreover, FPGAs benefit from much higher energy efficiency, which makes it a superior solution for accelerating BCNN in a data center setting. Early research effort [9] shows that GPU can get 7x speedup using a binary kernel for MNIST classification task on a binary multilayer perceptron (MLP). However, there have been very few studies on exploring FPGA-based accelerator architecture for binary neural networks.
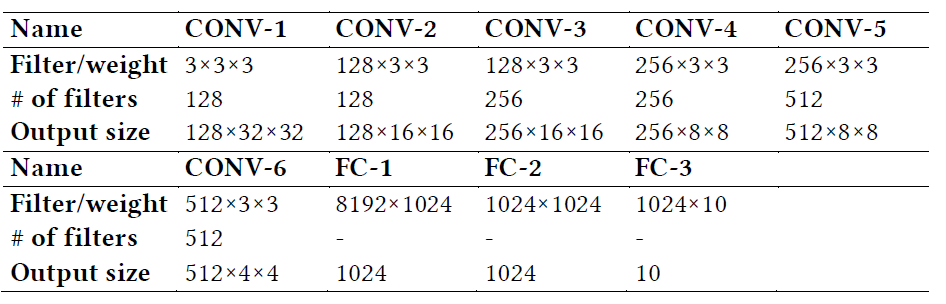
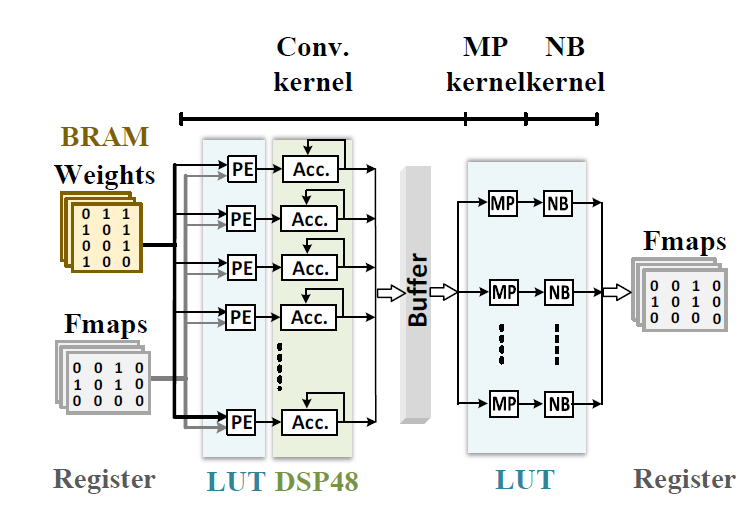
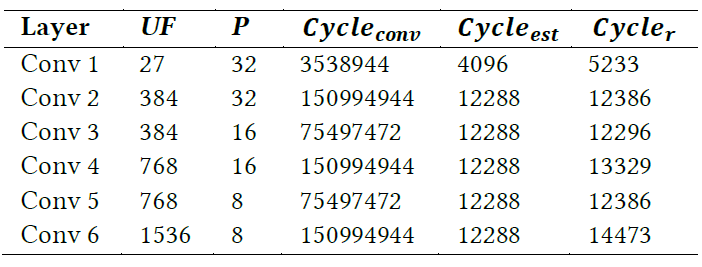
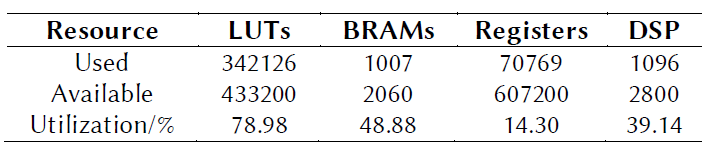
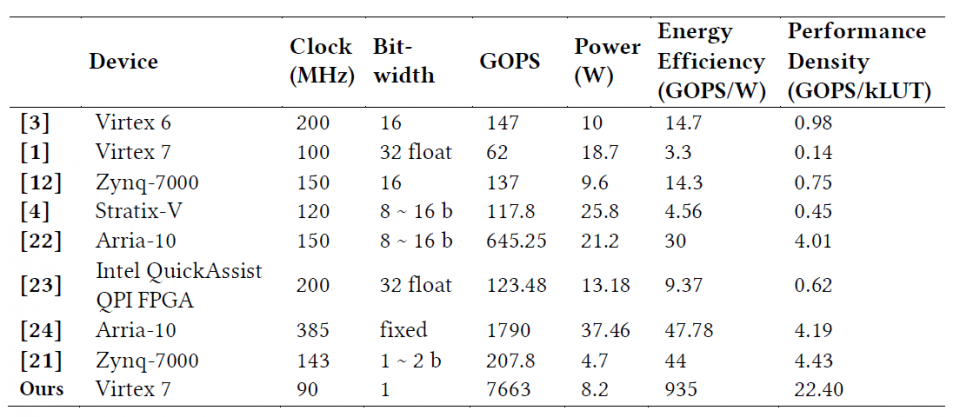
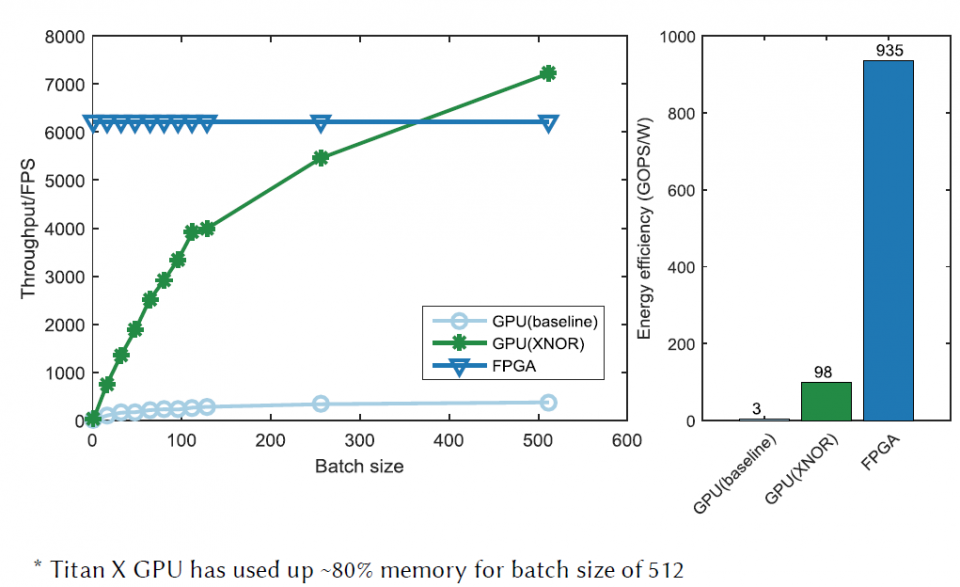
In this project, we propose an optimized FPGA accelerator architecture tailored for BCNN. The proposed architecture was adopted to implement a 9-layer BCNN on a Xilinx Virtex-7 XC7VX690 FPGA, which achieves nearly state-of-the-art classification accuracy on CIFAR-10. The experiment results show that the FPGA implementation outperforms its optimized GPU counterpart with 75x higher energy efficiency and 8.3x higher throughput for processing a small batch size of 16 images (e.g. from individual online request). For processing a large batch size of 512 images (e.g. from static data), the FPGA implementation achieves comparable throughput with 9.5x higher energy efficiency compared with the GPU counterpart.
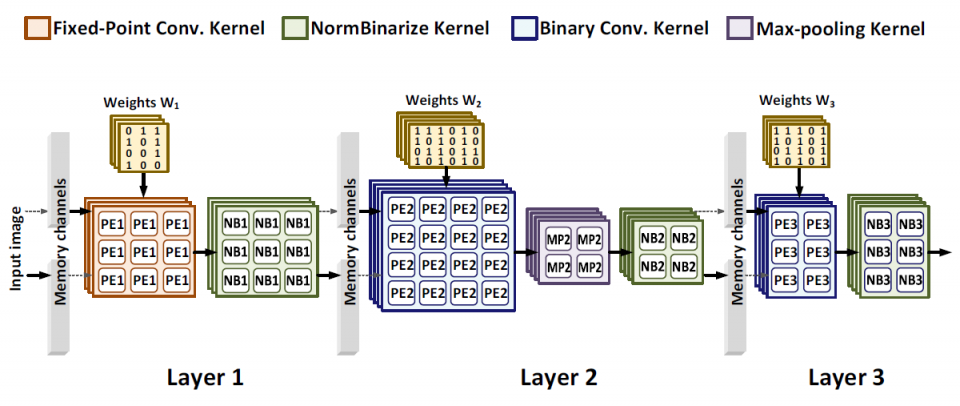
Thus, BCNNs are ideal for efficient hardware implementations on FPGAs regardless of the size of workload. The bitwise operations in BCNNs allow for the efficient hardware mapping of convolution kernels using LUTs, which is the key to enable massive computing parallelism on an FPGA. Applying the optimal levels of architectural unfolding, parallelism, and pipelining based on the proposed throughput model is the key to maximizing the system throughput. Building memory channels across layers with data-flow control is the key to constructing a streaming architecture to further improve the throughput.
This work by Arizona State University and Nanyang Technological University is supported by Cisco Research Center (CG#594589) and Singapore MOE Tier-2 (MOE2015-T2-2-013), respectively. We acknowledge Mr. Skip Booth and Mr. Hugo Latapie from Cisco for fruitful research discussions. We also thank Xilinx University Program for donating the FPGA boards.
Copyright © 2015-2024 Parallel Systems and Computing Laboratory. All right reserved. | Site Admin: Fengbo Ren | Powered by Drupal.


