Sign In / Sign Out
Navigation for Entire University
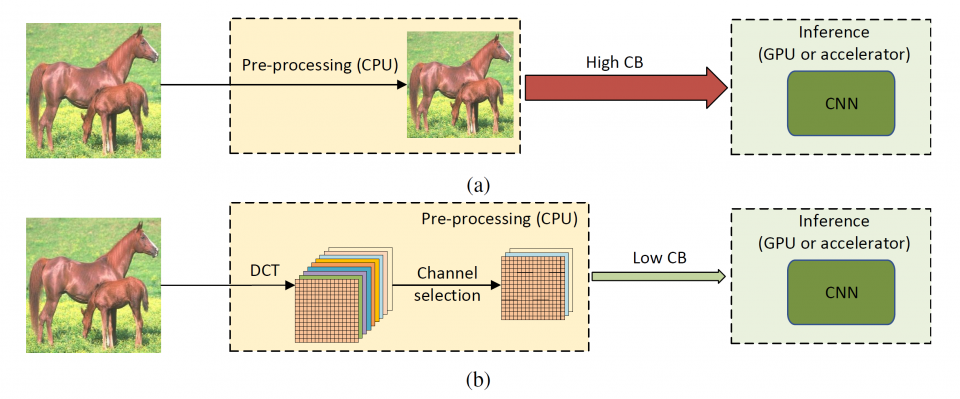
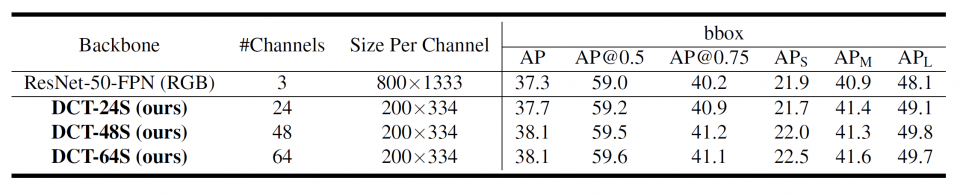
Convolutional neural networks (CNNs) have revolutionized the computer vision community because of their exceptional performance on various tasks such as image classification, object detection, and semantic segmentation. Constrained by the computing resources and memory limitations, most CNN models only accept RGB images at low resolutions (e.g., 224 ⇥ 224). How- ever, images produced by modern cameras are usually much larger. For example, the high definition (HD) resolution images (1920⇥1080) are considered relatively small by mod- ern standards. Even the average image resolution in the ImageNet dataset is 482⇥415, which is roughly four times the size accepted by most CNN models. Therefore, a large portion of real-world images are aggressively down- sized to 224⇥224 to meet the input requirement of classification networks. However, image downsizing inevitably incurs information loss and accuracy degradation. Prior works aim to reduce information loss by learning task-aware downsizing networks. However, those networks are task-specific and require additional computation, which are not favorable in practical applications. In this research, we propose to reshape the high-resolution images in the frequency domain, i.e., discrete cosine transform (DCT) do- main 1, rather than resizing them in the spatial domain, and then feed the reshaped DCT coefficients to CNN models for inference. Our method requires little modification to the existing CNN models that take RGB images as in- put. Thus, it is a universal replacement for the routine data pre-processing pipelines. We demonstrate that our method achieves higher accuracy in image classification, object detection, and instance segmentation tasks than the conventional RGB-based methods with an equal or smaller input data size. The proposed method leads to a direct reduction in the required inter-chip communication bandwidth that is often a bottleneck in modern deep learning inference systems, i.e., the computational throughput of rapidly evolving AI accelerators/GPUs is becoming increasingly higher than the data loading throughput of CPUs, as shown in Figure 1.
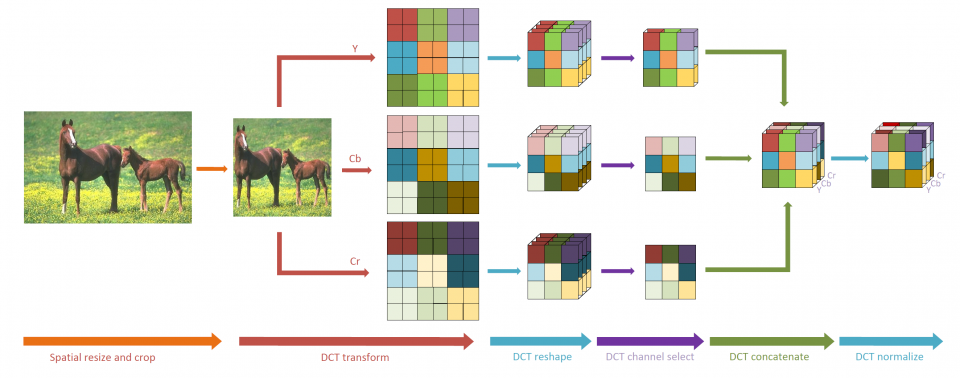
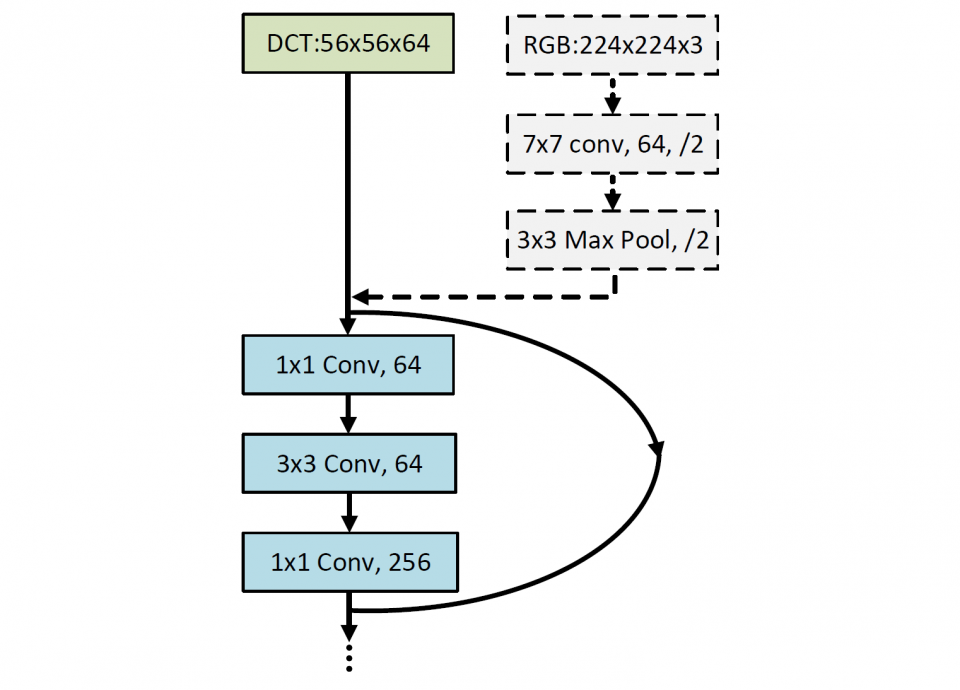
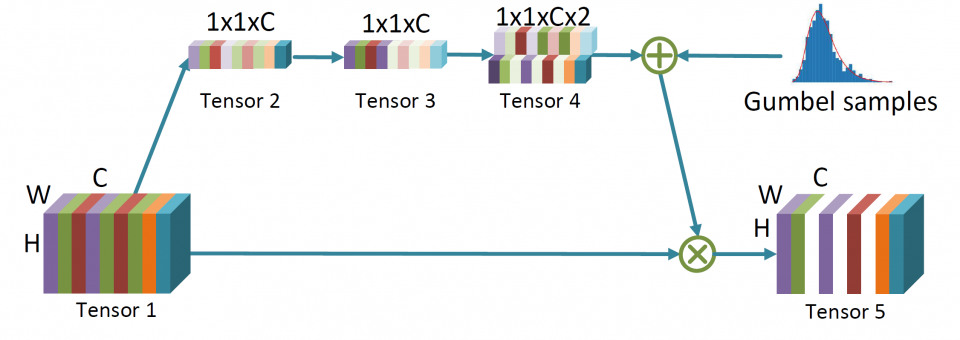
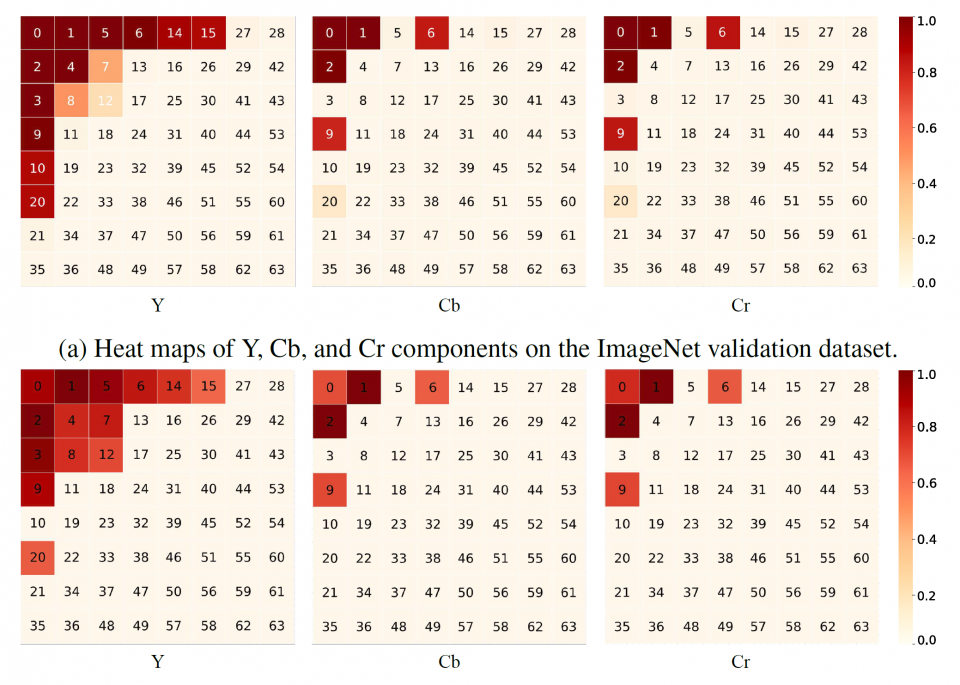
Inspired by the observation that human visual system (HVS) has unequal sensitivity to different frequency components, we analyze the image classification, detection and segmentation task in the frequency domain and find that CNN models are more sensitive to low-frequency channels than the high-frequency channels, which coincides with HVS. This observation is validated by a learning-based channel selection method that consists of multiple “on-off switches”. The DCT coefficients with the same frequency are packed as one channel, and each switch is stacked on a specific frequency channel to either allow the entire channel to flow into the network or not.
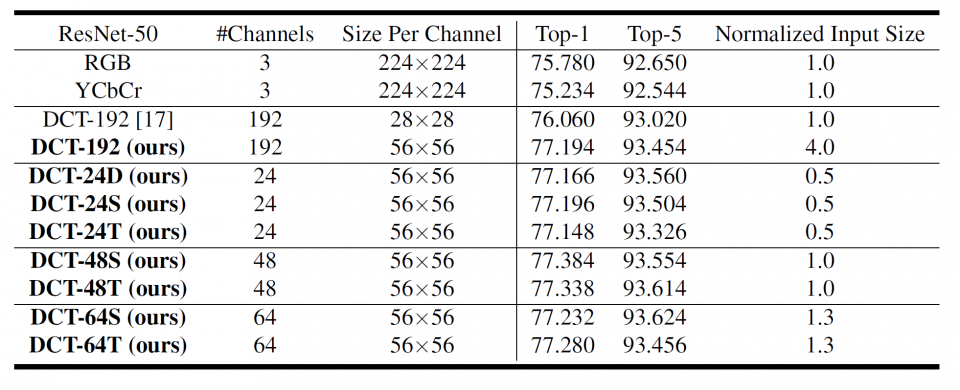
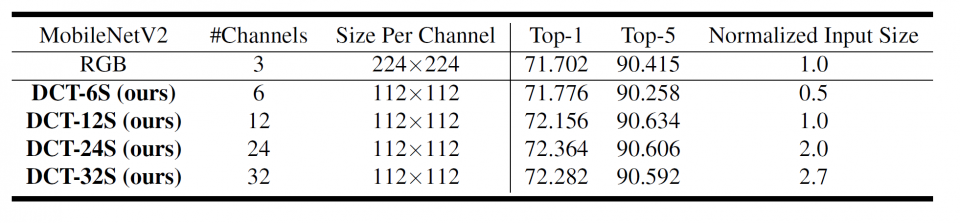
Using the decoded high-fidelity images for model training and inference has posed significant challenges, from both data transfer and computation perspectives. Due to the spectral bias of the CNN models, one can only keep the important frequency channels during inference without losing accuracy. In this research, we also develop a static channel selection approach to preserve the salient channels rather than using the entire frequency spectrum for inference. Experiment results show that the CNN models still retain the same accuracy when the input data size is reduced by 87.5%.
The contributions of this research are as follows:




The work by Arizona State University is supported by an NSF grant (IIS/CPS-1652038).
Copyright © 2015-2024 Parallel Systems and Computing Laboratory. All right reserved. | Site Admin: Fengbo Ren | Powered by Drupal.





