High-frame-rate cameras are capable of capturing videos at frame rates over 100 frames per second (fps). These devices were originally developed for research purposes, e.g., to characterize events which occur at a rate that is higher than traditional cameras are capable of recording in physical and biological science. Some high-end frame-rate cameras, such as Photron SA1, SA3, are capable of recording high resolution still images of ephemeral events such as a supersonic Flying bullet or an exploding balloon with negligible motion blur and image distortion artifacts. However, due to the complex sensor hardware designed for high sampling frequency, these equipment is extremely expensive. The high cost (over tens of thousand dollars for one camera) limits the field of their applications. Furthermore, the high transmission bandwidth and the large storage space associated with the high frame rate challenges the manufacture of affordable consumer devices. For example, true high-definition resolution (1080p) video cameras at a frame rate of 10k fps can generate about 500 GB data per second, which imposes significant challenges for existing transmission and storing techniques. In addition, the high throughput raises energy efficiency a big concern. For example, “GoPro 5” can capture videos at 120 fps with 1080p resolution. However, the short battery life (1-2 hours) has significantly narrowed their practical applications.
Traditional video encoder, e.g., H.264/MPEG-4, is composed of motion estimation, frequency transform, quantization, and entropy coding modules. From both speed and cost perspectives, the complicated structure makes these video encoder unsuitable for high-frame-rate video cameras. Alternatively, compressive sensing (CS) is a much more hardware-friendly acquisition technique that allows video capturing with a sub-Nyquist sampling rate. The advent of CS has led to the emergence of new image devices, e.g., single-pixel cameras [6]. CS has also been applied in many practical applications, e.g., accelerating magnetic resonance imaging (MRI) [12]. While traditional signal acquisition methods follow a sample-then-compress procedure, CS could perform compression along with sampling. The novel acquisition strategy has enabled low-cost on-sensor data compression, relieving the pain for high transmission bandwidth and large storage space. In the recent decade, many algorithms have been proposed [3, 15, 1, 4, 20, 2] to solve the CS reconstruction problem. Generally, these reconstruction algorithms are based on either optimization or greedy approaches using signal sparsity as prior knowledge. As a result, they all suffer from high computational complexity, which requires seconds to minutes to recover an image depending on the resolution. Therefore, these sparsity-based methods cannot satisfy the real-time decoding need of high-frame-rate cameras, and they are not appropriate for the high-frame-rate video CS application.
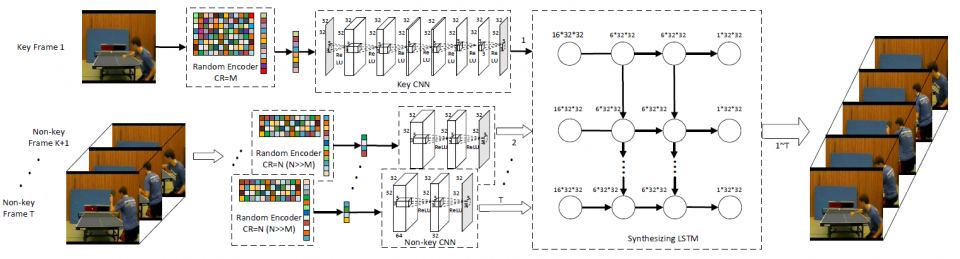
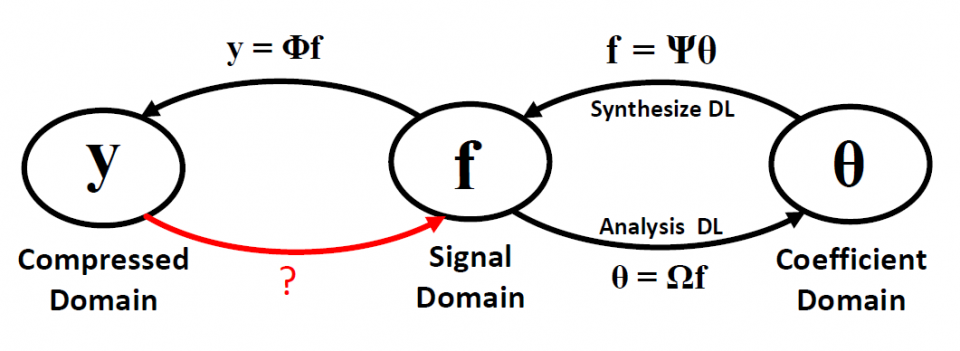
The slow reconstruction speed of conventional CS approaches motivates us to directly model the inverse mapping from compressed domain to original domain, which is shown in Figure 2. Usually, this mapping is extremely complicated and difficult to model. However, the existence of massive unlabeled video data gives a chance to learn such a mapping using data-driven methods. In this project, we design an enhanced Recurrent convolutional neural network (RCNN) to solve this problem. RCNN has shown astonishingly good performance for video recognition and description [5, 21, 23, 19]. However, conventional RCNNs are not well suited for video CS application, since they are mostly designed to extract discriminant features for classification related tasks. Simultaneously improving compression ratio (CR) and preserving visual details for high-fidelity reconstruction is a more challenging task. In this work, we develop a special RCNN, called “CSVideoNet”, to extract spatial-temporal features, including background, object details, and motions, to significantly improve the compression ratio and recovery quality trade-o for video CS application over existing approaches.
The highlights of this work are summarized as follows:
-
We propose an end-to-end and data-driven framework for video CS. The proposed network directly learns the inverse mapping from the compressed videos to the original input with no pre/post-processing. To the best of our knowledge, there has been no published work that addresses this problem using similar methods.
-
We propose a multi-level compression strategy to improve CR with the preservation of high-quality spatial resolution. Besides, we perform implicit motion estimation to improve temporal resolution. By combining both spatial and temporal features, we further improve the compression ratio and recovery quality trade-o without increasing much computational complexity.
-
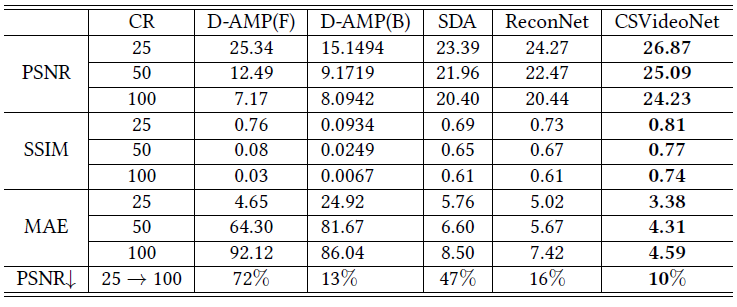
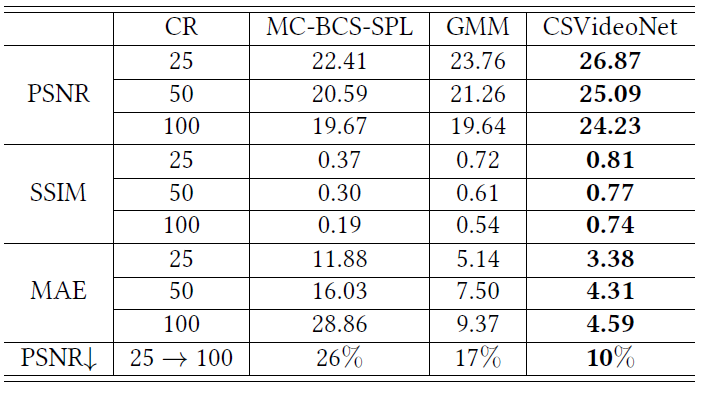
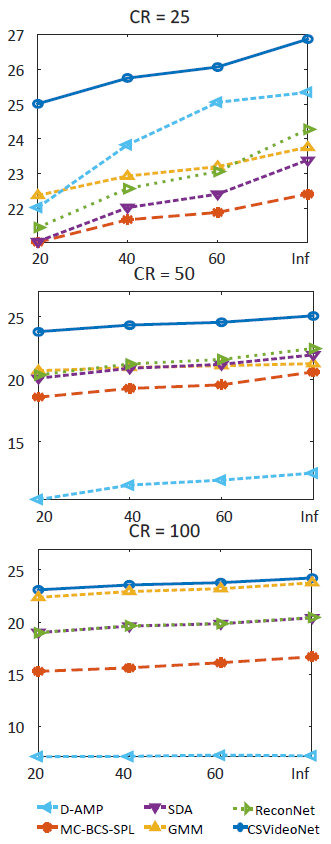
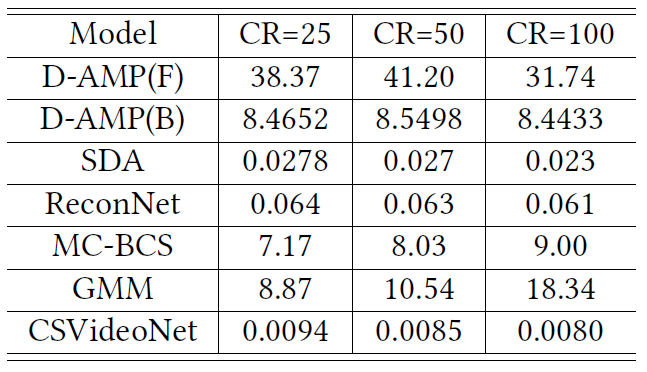
We demonstrate CSVideoNet outperforms the reference approaches not only in recovery quality but also in reconstruction speed because of its non-iterative nature. It enables real-time high-delity reconstruction for high-frame-rate videos at high CRs. We achieve state-of-the-art performance on the large-scale video dataset UCF-101. Specically, CSVideoNet reconstructs videos at 125 fps on a Titan X GPU and achieves 25dB PSNR at a 100x CR.