Sign In / Sign Out
Navigation for Entire University
The Internet-of-Things (IoT) will connect 50 billion devices and is expected to generate 400 Zetta Bytes of data per year by 2020. Even considering the fast-growing size of the cloud infrastructure, the cloud is projected to fall short by two orders of magnitude to either transfer, store, or process such vast amount of streaming data. Furthermore, the cloud-based solution will not be able to provide timely service for many time-sensitive IoT applications. Consequently, the consensus in the industry is to expand our computational infrastructure from data centers towards the edge. Over the next decade, a vast number of edge servers will be deployed to the proximity of IoT devices; a paradigm that is now referred to as fog/edge computing.
There are fundamental differences between traditional cloud and the emerging edge infrastructure. The cloud infrastructure is mainly designed for (1) fulfilling timeinsensitive applications in a centralized environment; (2) serving interactive requests from end users; and (3) processing batches of static data loaded from memory/ storage systems. Differently, the emerging edge infrastructure has distinct characteristics, as it keeps the promise for (1) servicing time-sensitive applications in a geographically distributed fashion; (2) mainly serving requests from IoT devices, and (3) processing streams of data from various input/output (I/O) channels. Existing IoT workloads often arrive with considerable variance in data size and require extensive computation, such as in the applications of artificial intelligence, machine learning, and natural language processing. Also, the service requests from IoT devices are usually latency-sensitive. Therefore, having a predictable latency and throughput performance is critical for edge servers.
Existing edge servers on the market are simply a miniature version of cloud servers (cloudlet) which are primarily structured based on CPUs with tightly coupled co-processors (e.g., GPUs). However, CPUs and GPUs are optimized towards batch processing of memory data and can hardly provide consistent nor predictable performance for processing streaming data coming dynamically from I/O channels. Furthermore, CPUs and GPUs are power hungry and have limited energy efficiency, creating enormous difficulties for deploying them in energy- or thermal-constrained application scenarios or locations. Therefore, future edge servers call for a new general-purpose computing system stack tailored for processing streaming data from various I/O channels at low power consumption and high energy efficiency.
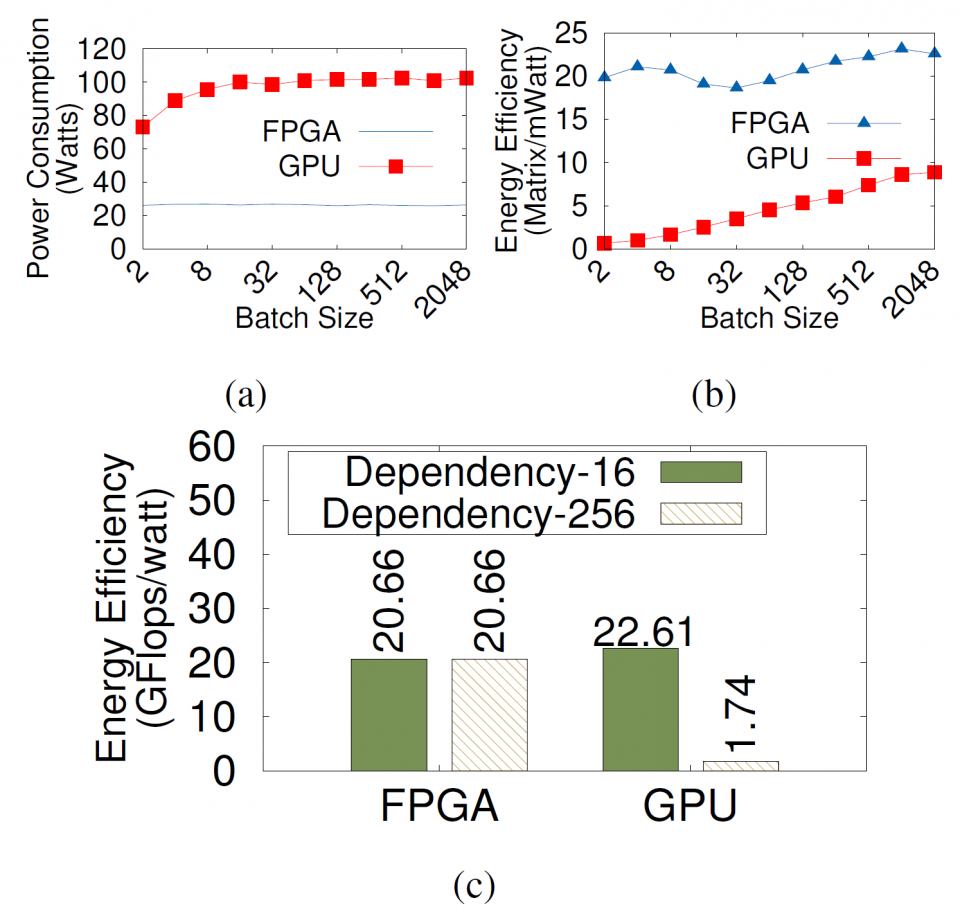
OpenCL-based field-programmable gate array (FPGA) computing is a promising technology for addressing the aforementioned challenges. FPGAs are highly energy-efficient and adaptive to a variety of workloads. Additionally, the prevalence of high-level synthesis (HLS) has made them more accessible to existing computing infrastructures. In this work, we study the suitability of deploying FPGAs for edge computing through experiments focusing on the following three perspectives: (1) sensitivity of processing throughput to the workload size of applications, (2) energy-efficiency, and (3) adaptiveness to algorithm concurrency and dependency degrees, which are important to edge workloads as discussed above.
The experiments are conducted on a server node equipped with a Nvidia Tesla K40m GPU and an Intel Fog Reference Design Unit equipped with two Intel Arria 10 GX1150 FPGAs. Experiment results show that (1) FPGAs can deliver a predictable performance invariant to the application workload size, whereas GPUs are sensitive to workload size; (2) FPGAs can provide 2.5– 30 times better energy efficiency compared to GPUs; and (3) FPGAs can adapt their hardware architecture to provide consistent throughput across a wide range of conditional or inter/intra-loop dependencies, while the GPU performance can drop by up to 14 times from the low- to high-dependency scenarios.

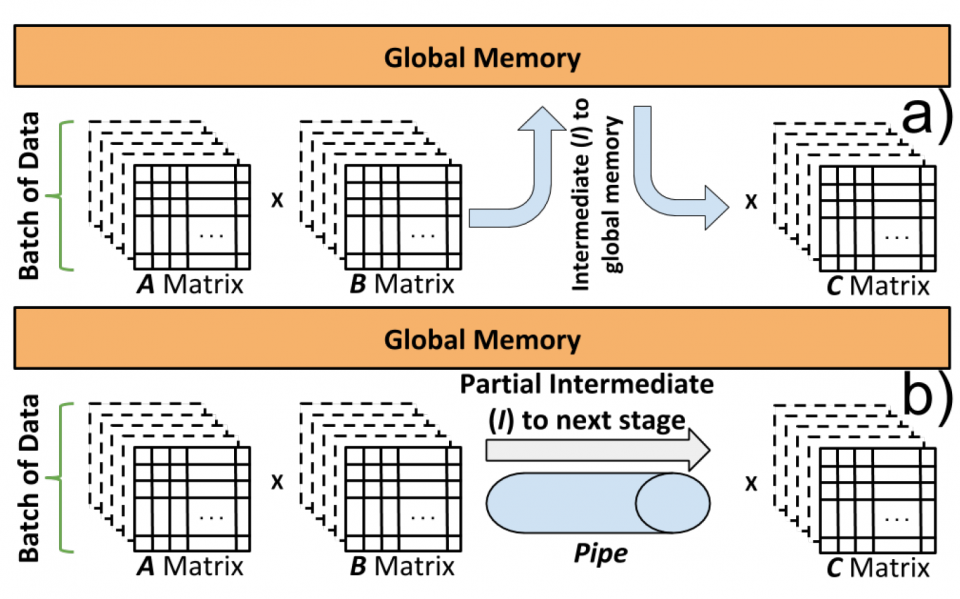
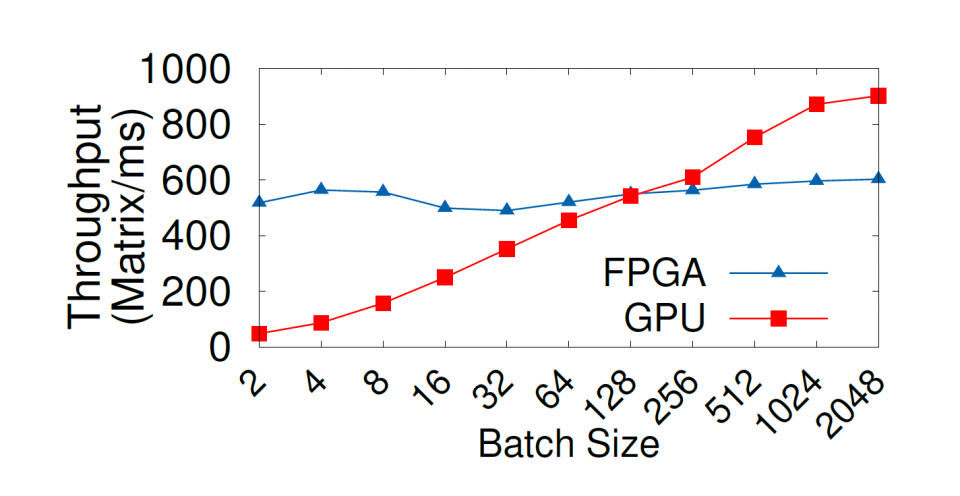
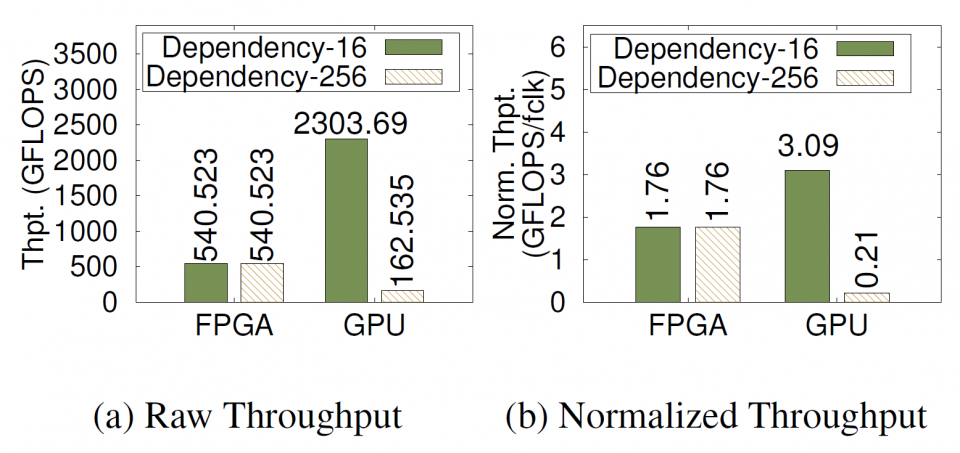
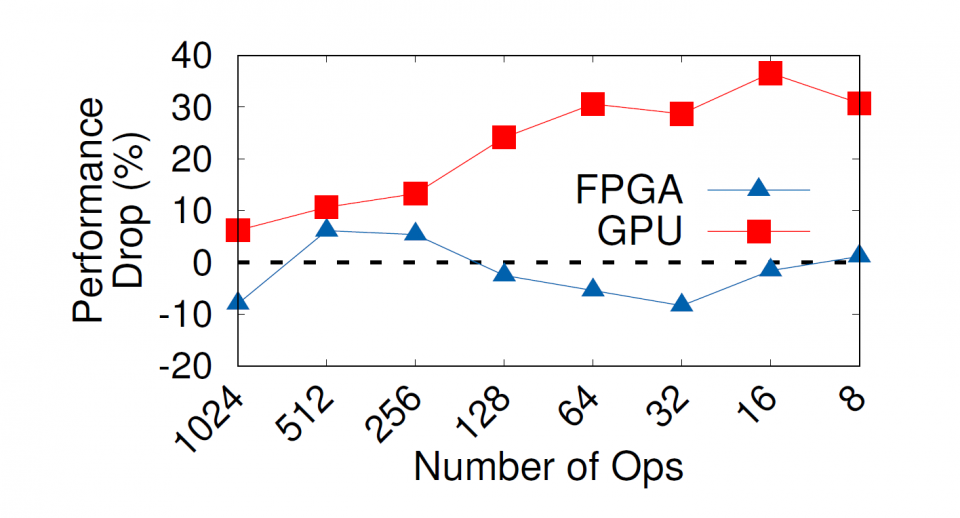
This work is supported by an NSF grant (CNS-1629888). We acknowledge Mr. Jason Seaholm from Intel for providing us early access to Intel Fog Reference Design units. We also thank Intel FPGA University Program for donating the FPGA boards.
Copyright © 2015-2024 Parallel Systems and Computing Laboratory. All right reserved. | Site Admin: Fengbo Ren | Powered by Drupal.


