Sign In / Sign Out
Navigation for Entire University
Scene text interpretation is a critical part of natural scene interpretation, since the text probably contains more explicit information than the natural object. For instance, in a driving scenario, besides the standard road signs, textbased guide signs are essential in predicting the demand of lane changing. In a walking scenario, the name of the building or the store can help to make precise and reliable localization. Conventionally, text recognition has been vastly investigated for document images [1]. However, in the natural scene, the background is much more complicated than that of the document images, which makes the scene text recognition become a more challenging task. With the recent development in neural networks and deep learning [2] [3], the accuracy of natural scene text recognition has outperformed the traditional feature selection methods by using features selected automatically [4] [5]. The related work can be categorized as characterlevel based and word-level based solutions. The characterlevel based solutions [6] [7] detect and recognize character one at a time. Its front-end is a sliding window approach for character proposals, which makes it suffer from the processing time. The word-level based solution [8] requests large fullyconnected layer to generate the probability for thousands of word classes, which place a heavy burden on memory access. The shared limitation of either character-level [6] [7] or word-level based [8] solutions is that their architecture is not capable of achieving a low-latency performance. In [9], it performs one-shot text interpretation with a binary convolutional encoder-decoder network (B-CEDNet). Since most of the computation in B-CEDNet are bitwise operations, it opens a new opportunity for hardware acceleration.
However, all the previous work mentioned above is implemented by high-end GPUs (such as Nvidia Titan X). The power-hungry high-end GPUs are not able to be deployed on energy-constrained mobile devices. If GPUs are deployed on the server side, the communication overhead from a client to a cloud server is quite large, which sometimes even dominates the total processing time. However, long latency is not tolerant in augmented reality (AR) applications. If one chooses to use low-power oriented GPUs, such as Nvidia Tegra X1, on the power constrained edge devices, it will get 20x performance (in terms of Flops) degradation compared with the Nvidia Titan X GPU [10]. Considering the performance degradation factor, the frame rate in [9] will drop from 200 fps to 20 fps when it is mapped onto a Tegra X1. As such, it cannot maintain a real-time throughput on a lower-power GPU. In addition, the power consumption of a Tegra X1 is 6W [10], which is still too power hungry for a smartphone. Hence, an edge-computing oriented design is needed to solve this problem.
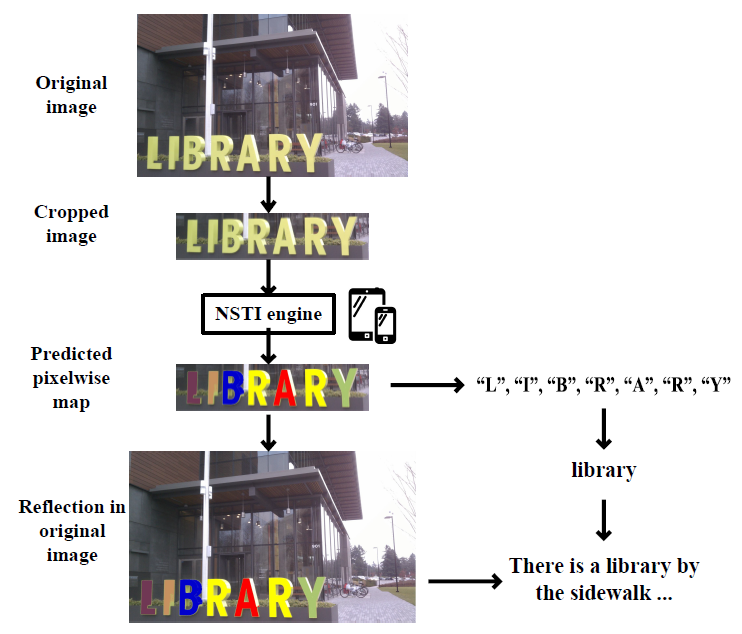
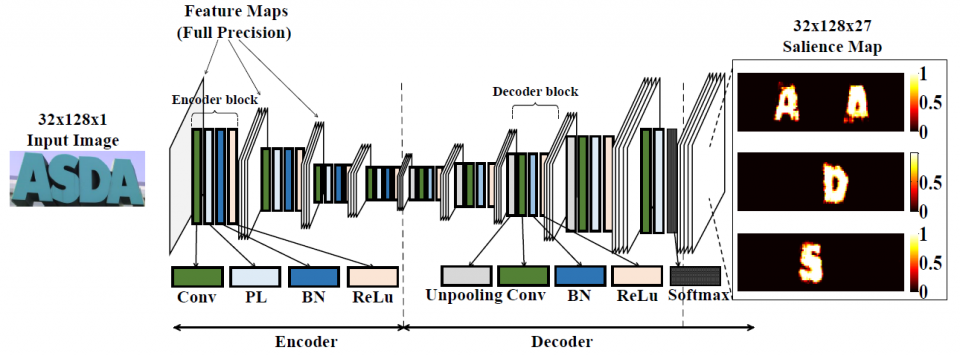
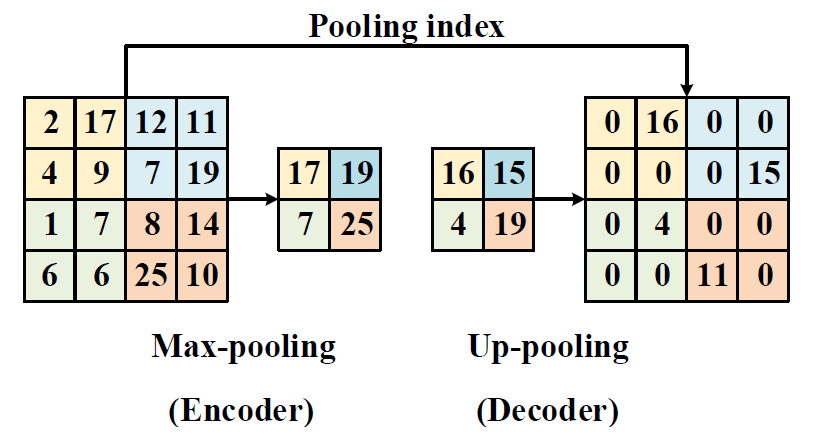
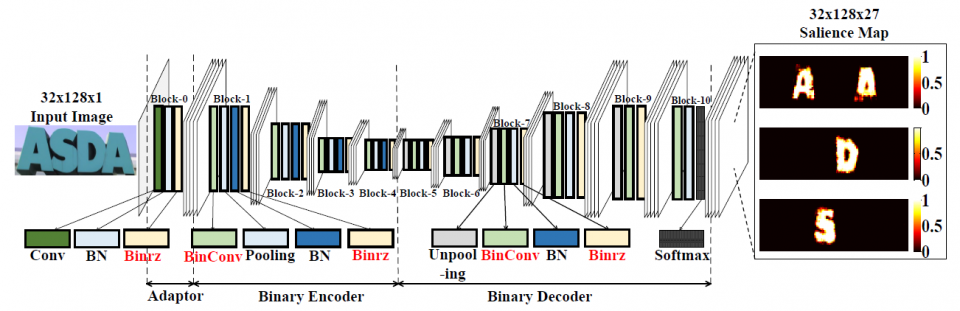
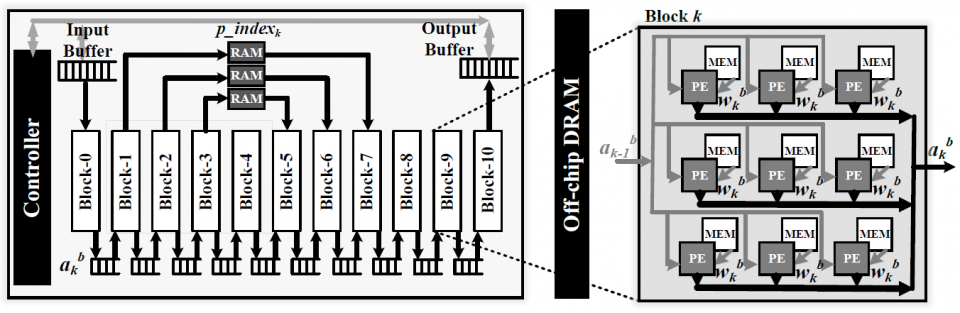
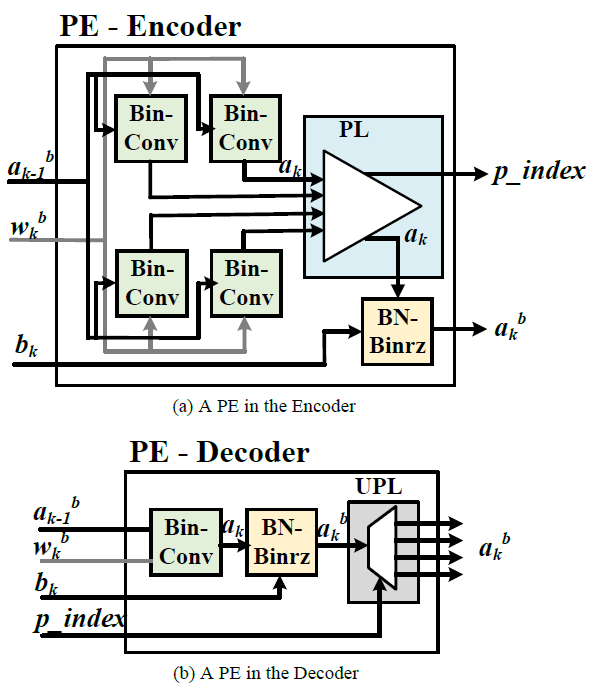
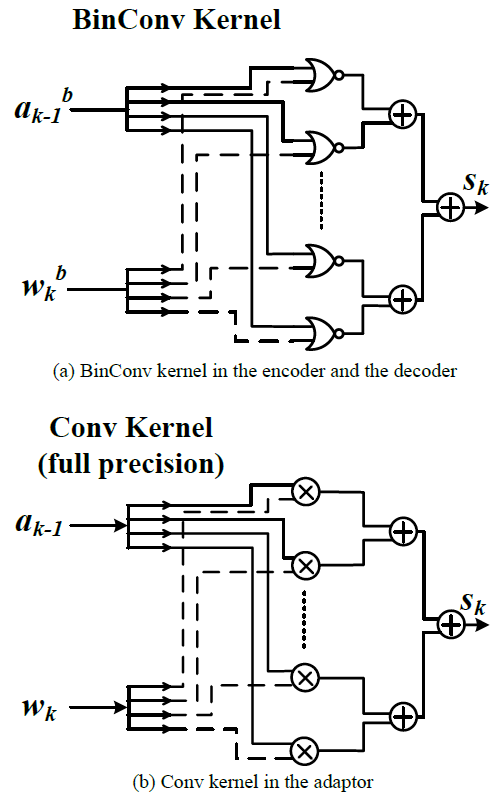
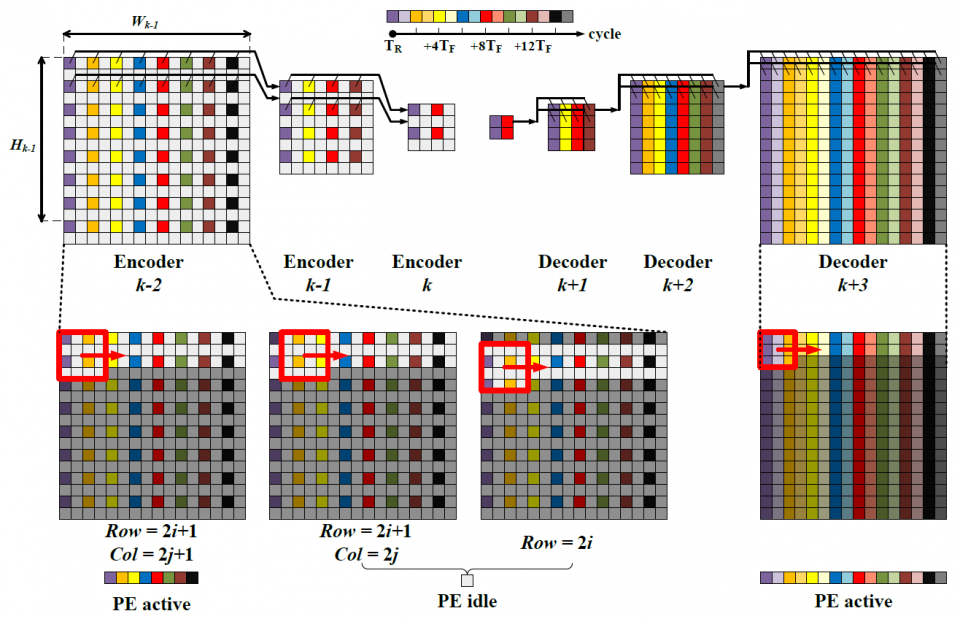
In this project, in order to target a low-latency and real-time processor for energy-efficient natural scene text processing on mobile devices, we propose an ASIC B-CEDNet-based natural scene text interpretation (NSTI) accelerator. As shown in Fig. 1, the processor takes the cropped natural scene image as the input and outputs a map of pixelwise classification results with the same size as input. In comparison with generating a bounding box for each character or the entire word (as shown in Fig. 2 (b) and (c)), the pixelwise classification output (in Fig. 2 (a)) shows morphological boundary, which is much more user-friendly in AR applications. Compared with binary classification results for the text and non-text regions in Fig. 2. (d), the proposed processor can identify different characters in a one-shot prediction. In addition, with the localization, morphological and categorized information, it largely alleviates the workload for the back-end word-level prediction and even scene description as shown in Fig. 1. The bitwise operation dominated computation in B-CEDNet enables massive parallelism of multiply-add operations (MACs) in the proposed processor. The binarized parameters and intermediate results are fully mapped on chip to eliminate the communication cost (regarding power consumption) instead of loading them from off-chip memory.
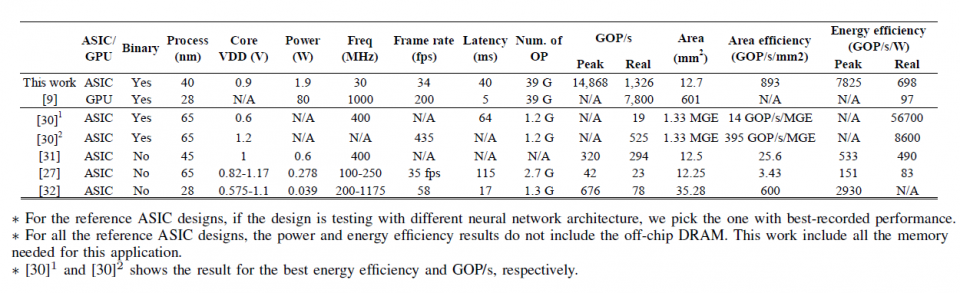
The NSTI accelerator is implemented in a 40nm CMOS technology, which can process scene text images (size of 128x32) at 34 fps and latency of 40 ms for pixelwise interpretation with the pixelwise classification accuracy over 90% on ICDAR- 03 and ICDAR-13 dataset. The real energy-efficiency is 698 GOP/s/W and the peak energy-efficiency can get up to 7825 GOP/s/W. The proposed accelerator is 7x more energy efficient than its optimized GPU-based implementation counterpart, while maintaining a real-time throughput with latency of 40 ms.

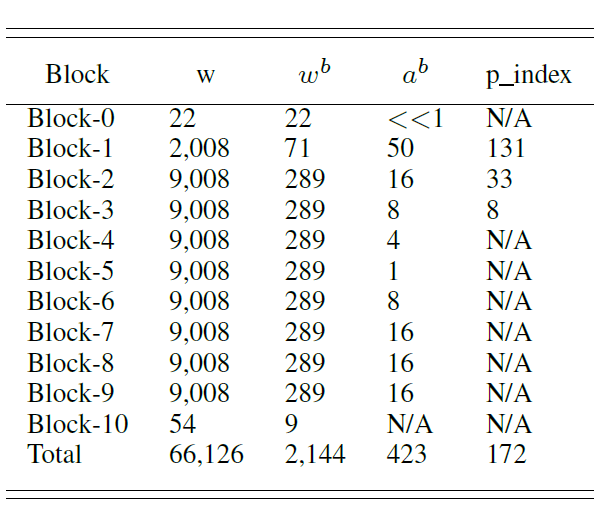
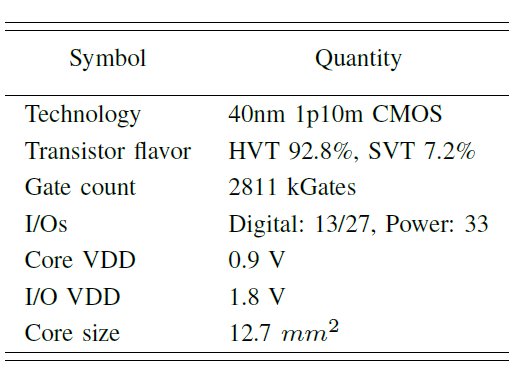
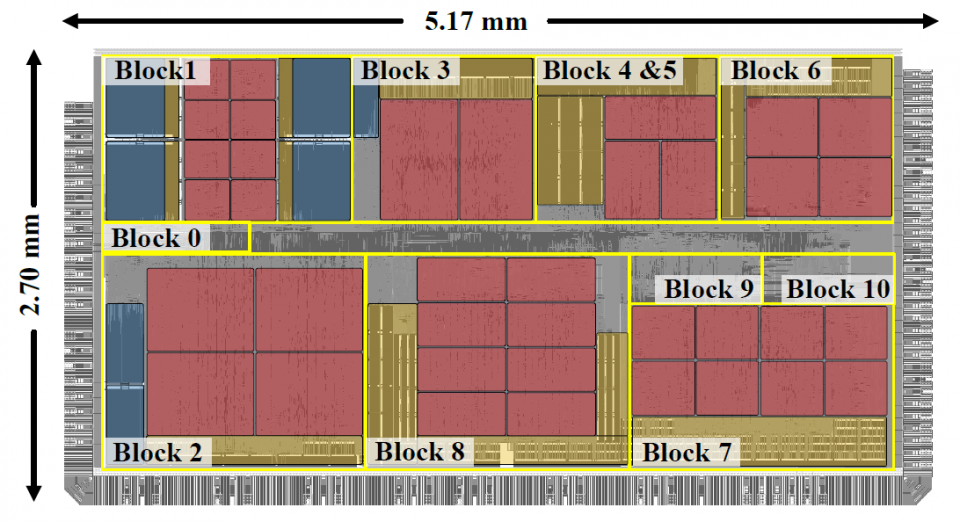

Arizona State University’s work is supported by NSF grant IIS/CPS-1652038.
Copyright © 2015-2024 Parallel Systems and Computing Laboratory. All right reserved. | Site Admin: Fengbo Ren | Powered by Drupal.



