Sign In / Sign Out
Navigation for Entire University
In the rapid evolution of deep learning, neural network models have been growing from several to over a hundred layers for handling more complex tasks. Network models are often trained with powerful GPUs in the cloud or on stand-alone servers, and the trained models are then deployed to certain hardware platforms for performing inference. For cloud applications where neural network models are both trained and deployed in the cloud, computational complexity is typically a secondary concern as there is little gap in computing resources between the training and the inference stages. However, in many emerging Internet-of- things (IoT) applications where neural network models must be deployed onto resource-constrained edge devices for performing real-time inference, the computational complexity of neural network models has become a major concern. Therefore, it is important to not only investigate how to build more compact neural network models that are friendly to hardware implementations but also rethink how to further compress compact neural network models for the efficient hardware implementations on resource-constrained edge devices.
The most compact form of deep neural networks are binary neural networks (BNNs). BNNs are an extreme case of a quantized neural network, which adopts binarized representations of weights and exclusive NOR (XNOR) operations as binary convolution. By applying binary constraints on deep neural networks, the existing studies have shown up to 12x, 5x, 16x speedup on a CPU, GPU, and field-programmable gate array (FPGA) implementation, respectively, compared with its 16/32- bit floating-point counterpart. Another popular method to compress neural networks is pruning. Pruning methods help to remove insensitive weights and/or connections of a network. Since quantization and pruning are independent on each other, they could be jointly applied. Existing work has already shown promising results of combining a 4-bit quantization with pruning for a deep compression. However, there has been no study that explores the pruning of BNNs. The major challenges of pruning BNNs are twofold. First, as both 0s and 1s are non-trivial in BNNs, it is not proper to adopt any existing pruning method of full-precision networks that interprets 0s as trivial. A new indicator is needed to identify the weights insensitive to network accuracy. Second, unstructured pruning can hardly result in any saving for BNNs as one has to introduce memory overhead to label the prunable weights that only have 1 bit. Therefore, we need a solution that avoids unstructured pruning.
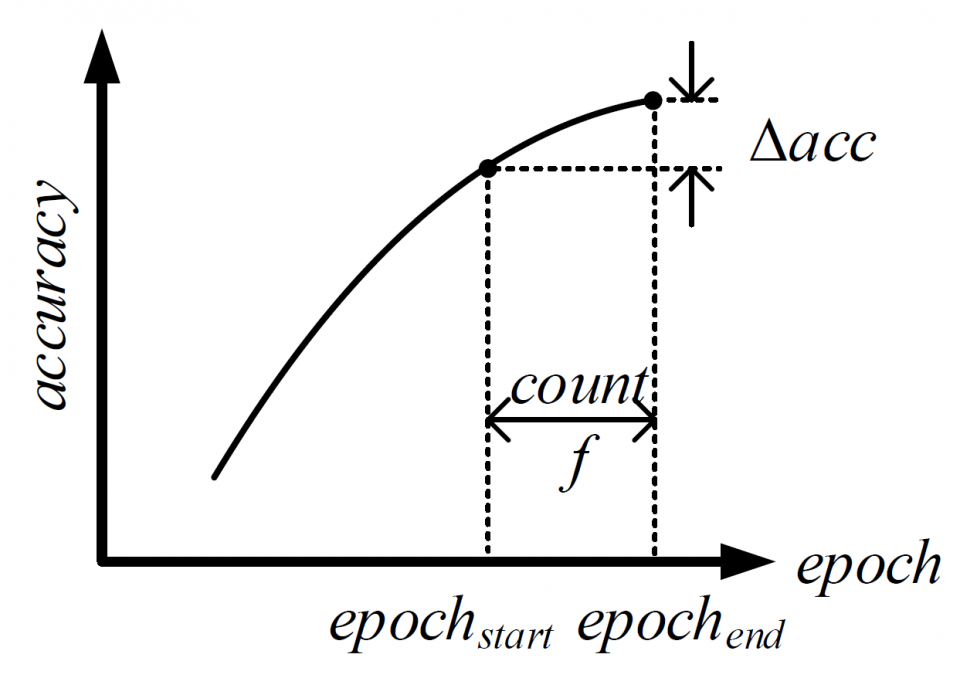
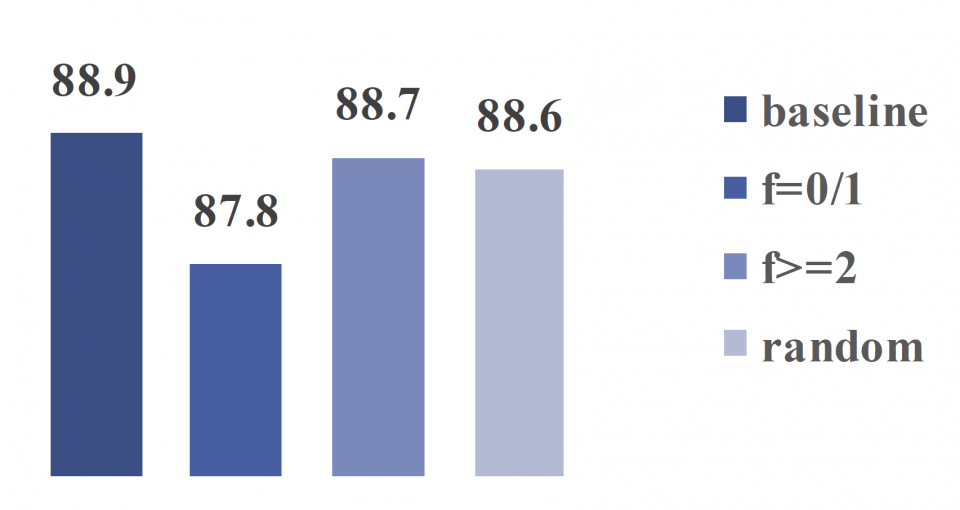
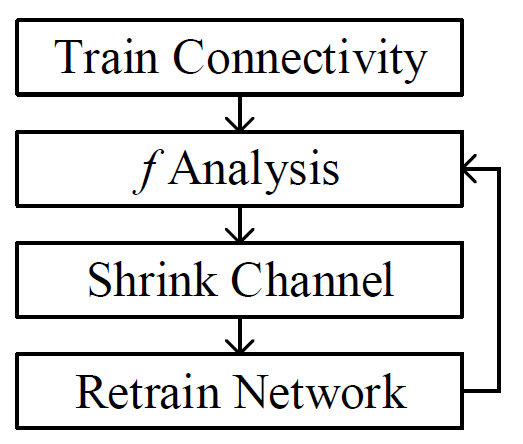
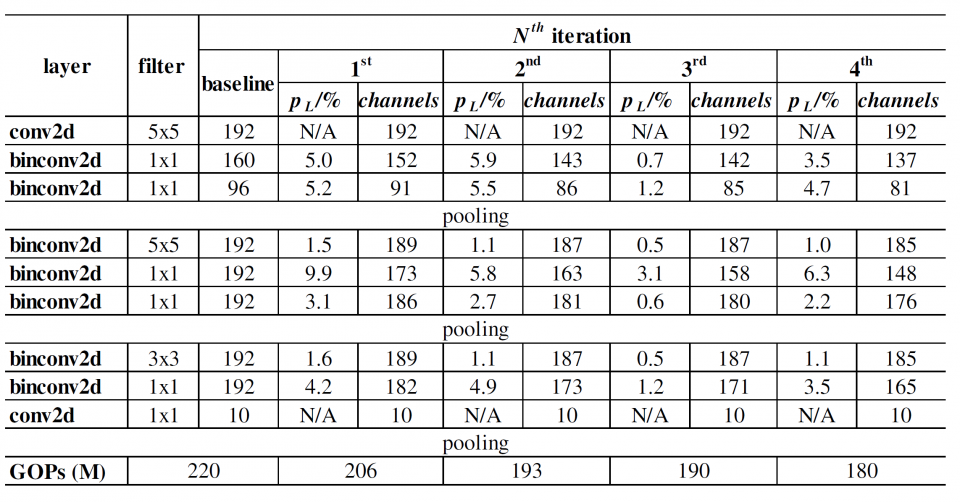
In this research, we propose a BNN-pruning method that uses the weight flipping frequency as an indicator to analyze the sensitivity of the binary weights to accuracy. Through experiments, we validate that the weights with a high weight flipping frequency, when the training is sufficiently close to convergence, are less sensitive to accuracy. To avoid unstructured pruning, we propose to shrink the number of channel in each layer by the same percentage of the insensitive weights to reduce the effective size of the BNN for further fine tuning. The experiments performed on the binary versions of a 9-layer Network-in-Network (NIN) and the AlexNet with the CIFAR-10 dataset show that the proposed BNN-pruning method can achieve 20-40% reduction in binary operations with 0.5-1.0% accuracy drop, which leads to a 15-40% runtime speedup on a TitanX GPU. The source code is available on GitHub.
The key contributions of this research are summarized as follows:

This work is supported by an NSF grant (IIS/CPS- 1652038) and an unrestricted gift (CG#1319167) from Cisco Research Center. The computing infrastructure used in this work is supported by an NFS grant (CNS-1629888). The four GPUs used for this research was donated by the NVIDIA Corporation.
Copyright © 2015-2024 Parallel Systems and Computing Laboratory. All right reserved. | Site Admin: Fengbo Ren | Powered by Drupal.

