Sign In / Sign Out
Navigation for Entire University
The Intemet-of-Things (IoT) boosts the vast amount of streaming data. Due to the limited bandwidth and the latency of cloud computing, it calls for the need of offloading the computing to decentralized edge computing infrastructures [1], On the other side, deep learning-based applications take the advantage of heavy computing resources for training large models to fit more and more complicated tasks. Even though the model performs well in terms of accuracy, its complexity may even make it impossible to be deployed on the edge devices. In order to enable more IoT services on edge devices, it is essential to study the effective computation and accuracy trade-off of the deep learning-based models and tailor it for IoT services on edge devices.
Object detection is the key module in face detection, tracking objects, video surveillance, pedestrian detection, etc. With the recent development of deep learning, it boosts the performance of object detection tasks. However, regarding the computational complexity (in terms of FLOPs), a detection network can possibly consume three orders of magnitude more FLOPs than a classification network, which makes it much more challenging to be deployed on an edge device.
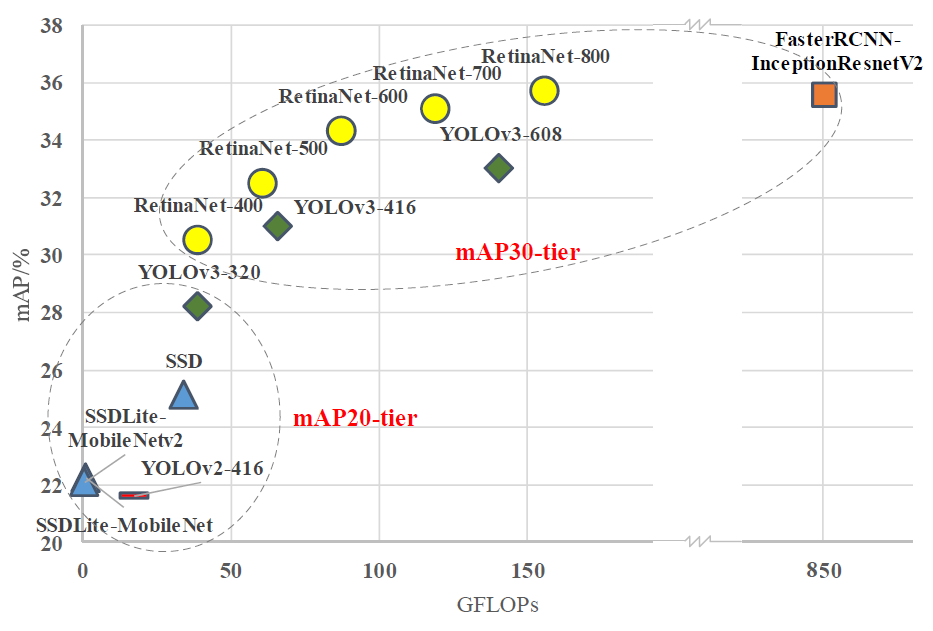
With detection on edge devices, convenience stores with gas stations can do real-time analysis of customers’ age and gender for personalized on-screen recommendation. Comparing to detection in self-driving cars, a hard real-time scenario (30fps), the in-store real-time recommendation system only needs a soft real-time response (1-2 fps) and also has a certain tolerance of the accuracy rate. To hit this target frame rate with edge devices, the reasonable object detection solutions fall in the upper mid range - mAP-30-tier.
In this project, we use the mAP as the indicator to categorize the existing object detection solutions. The mAP-20- tier solutions are the most aggressive ones that target highly energy- and resource-constrained devices, such as battery- powered mobile devices. The existing solutions, such as YOLOvl, YOLOv2, SSD, MobileNetv2-SSDLite have pushed hard to reduce the memory consumption by trading off their accuracy performance. Their detection accuracy on the large dataset (COCO test-dev 2017) yields to mAP of 22-25%. The mAP-40-tier solutions, such as MaskRCNN and its variations, on the contrary, are targeting the best mAP performance with less concern about computation resources. The mAP-30-tier solutions do not sacrifice the accuracy performance too much but are more aware of the computational efficiency. In the mAP-30-tier, popular solutions include Faster R-CNN, RetinaNet, YOLOv3, and their variants. These solutions can be potentially deployed on edge GPUs (e.g., Nvidia T4 GPU) or FPGAs (e.g., Intel Arria 10 FPGA based acceleration card), since the on-board memory resources are generally enough for preloading the weights of the mAP-30-tier networks verifies the linear relation between FLOP count and inference runtime for the same kind of network.
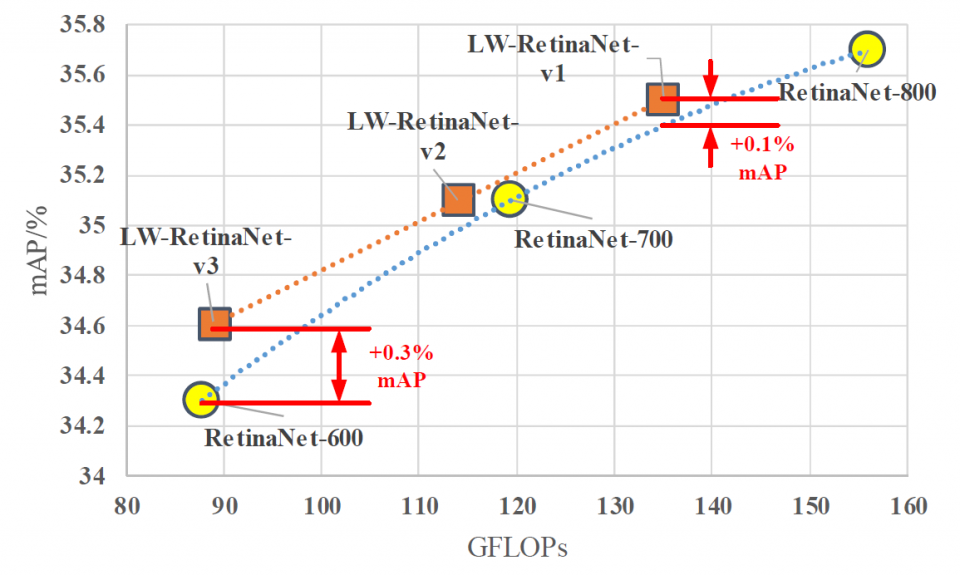
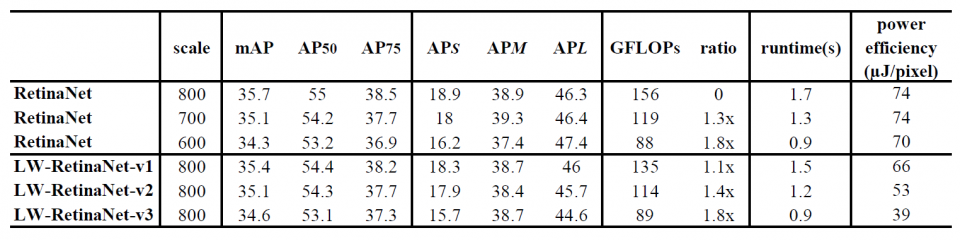
The overview of the FLOP-mAP profile of the existing mAP-20-tier and mAP-30-tier detection networks are shown in Fig. 1. The upper-left comer is the preferred comer in the FLOP-mAP plane. We take the RetinaNet as the baseline since it has the best FLOP-mAP trade-off in the mAP-30-tier. We use the FLOP count as a key indicator for comparison. By applying Faster R-CNN, RetinaNet and YOLOv3 on the same task for COCO detection dataset, which takes an input image around 600 x 600-800x 800, the mAP will hit in the range of 33%-36%. However, the FLOPs of Faster R-CNN is around 850 GFLOPs (gigaFLOPs), which is at least 5x more than that of RetinaNet and YOLOv3. Apparently, Faster R-CNN is not competitive in terms of computational efficiency. From YOLOv2 to YOLOv3, it is interesting that the authors have aggressively increased the number of FLOPs from 30 to 140 GFLOPs to gain mAP improvement from 21% to 33%. Even with that, the mAP of YOLOv3 is 2.5% lower than RetinaNet with 150 GFLOPs. Also, a low-end version of MaskRCNN with mAP of 37.8% cannot beat RetinaNet in terms of runtime. These observations inspire us to take the RetinaNet as the baseline to explore the feasibility of creating a light-weight version of it.
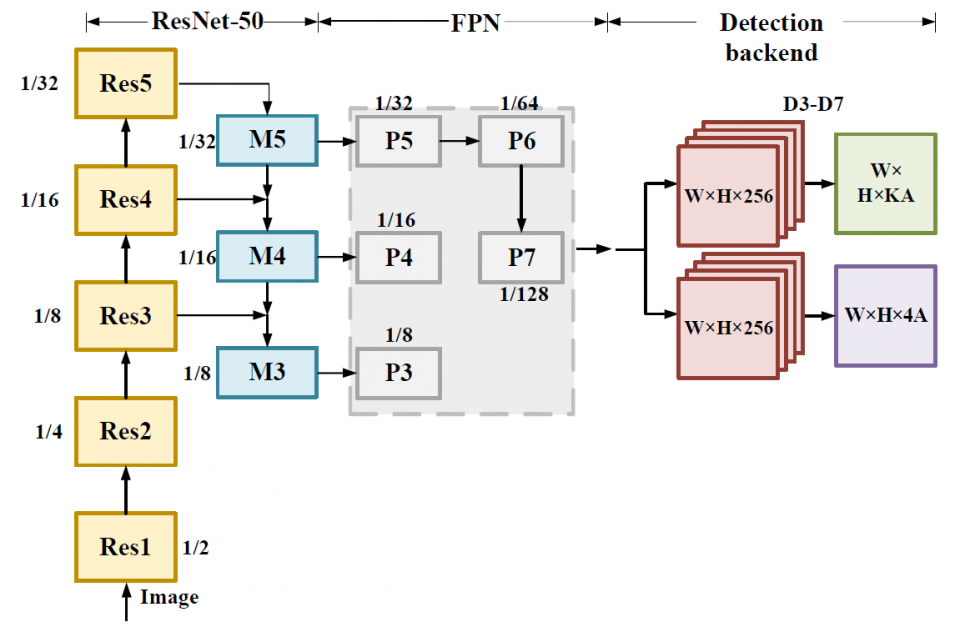
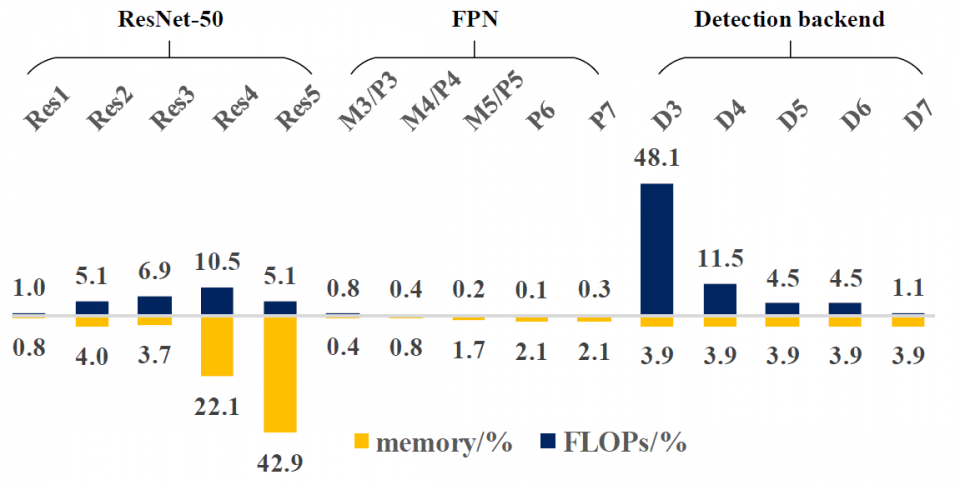
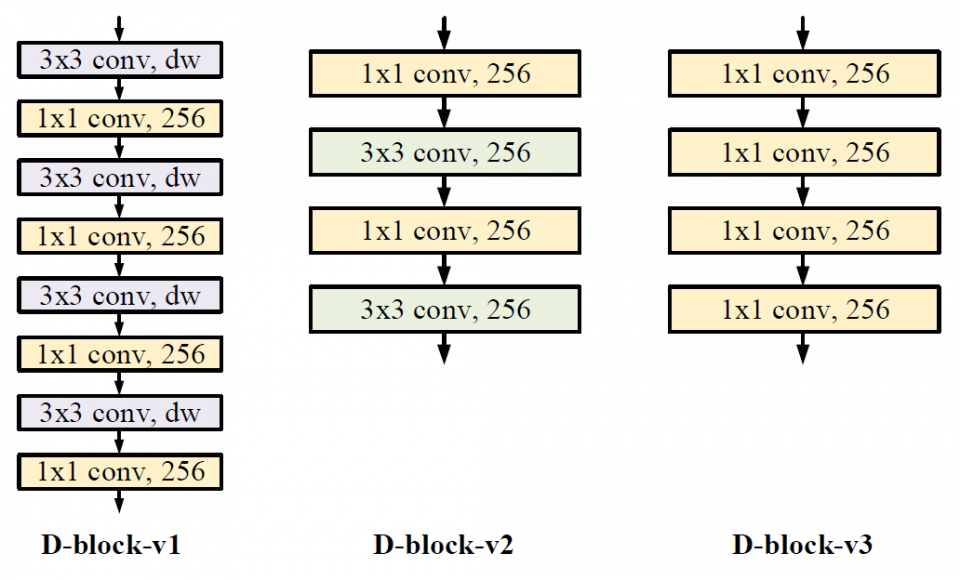
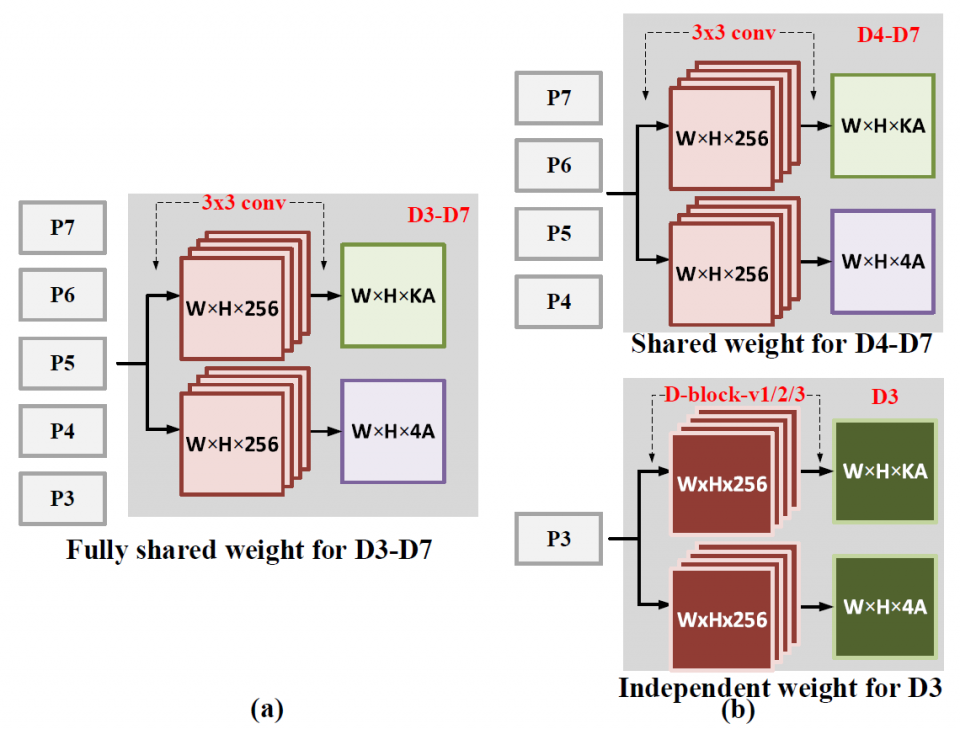
There are two common methods to reduce the FLOPs in a detection network. One way is to switch to another backbone, while the other is to reduce the input image size. The first method results in noticeable accuracy drop if one substitutes a ResNet backbone with a more shallow one. Typically it is not considered as a good accuracy-FLOP trade-off scheme with a small variation. With regard to reducing the input image size, it is an intuitive way to reduce the FLOPs. However, the accuracy-FLOP trade-off curve shows degradation in a polynomial trend, There is an opportunity to find a more linear degradation tendency curve for a better accuracy-FLOP trade-off. We propose only to replace certain branches/layers of the detection network with light-weight architecture and keep the rest of the network unchanged. For the RetinaNet, the heaviest branch is the succeeding layers of the finest FPN (P3 in Fig. 2), which takes up to 48% of the total FLOPs. We propose different light-weight architecture variants. Moreover, the proposed method can also be applied to other blockwise-FLOPs-imbalance detection networks.
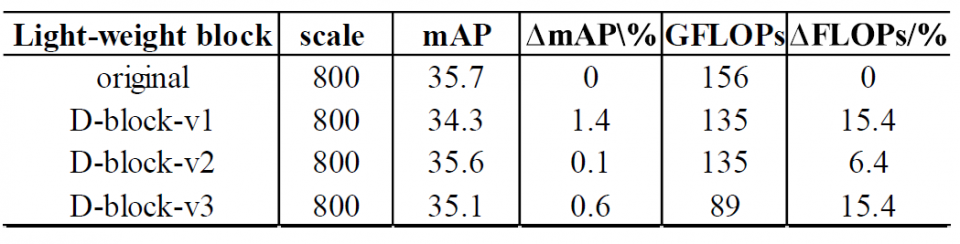
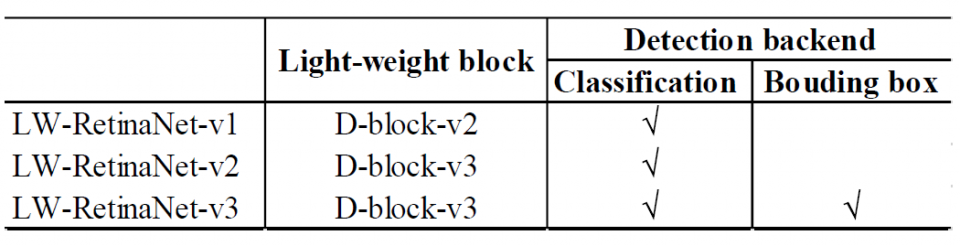
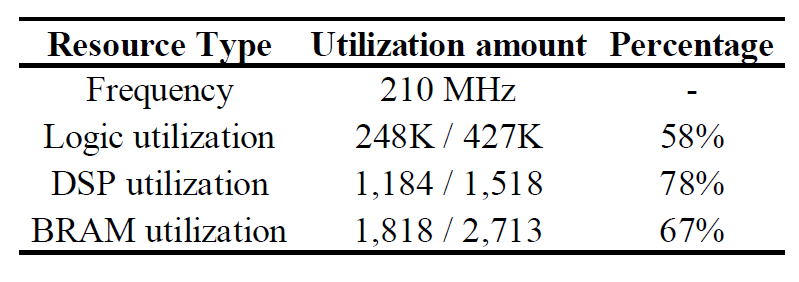
The contribution of this paper is three-fold. First, we analyze the accuracy-computation trade-off of RetinaNet and propose a light-weight RetinaNet model structure by simplifying the heaviest bottleneck layer. Second, we illustrate that the proposed light-weight RetinaNet has a constantly better FLOP- mAP trade-off curve (linear degradation) than a naive input image scaling approach (polynomial degradation). Third, we quantitatively evaluate the runtime performance on an FPGA- based edge node and show that the proposed method results in 0.3% mAP improvement at 1.8x FLOP reduction with no sacrifice in runtime, compared with input image scaling method.
This work is supported by an NSF grant (IIS/CPS-1652038) and an unrestricted gift from Radius AI, Inc. The computing infrastructure used in this work is supported by an NFS grant (CNS-1629888). The Arria 10 GX FPGA Development Kits used for this research was donated by Intel FPGA University Program. We thank Dr. Aykut Dengi and Bobby Chowdary from Radius AI, Inc. for fruitful research discussions.
Copyright © 2015-2024 Parallel Systems and Computing Laboratory. All right reserved. | Site Admin: Fengbo Ren | Powered by Drupal.


