Sign In / Sign Out
Navigation for Entire University
Vision-based applications can be found in many embedded devices for classification, recognition, detection and tracking tasks [Tian et al., 2015; Hu et al., 2015]. Specifically, convolutional neural network (CNN) has become the core architecture for those vision-based tasks [LeCun et al., 2015]. Since it can outperform conventional feature selection-based algorithm in terms of accuracy, it becomes more and more popular. Advanced driver-assistance system (ADAS) can either used CNNs for guiding autonomous driving or alerting the driver of predicted risk [Tian et al., 2015]. It is obvious that ADAS depends on a low-latency system to get a timely reaction. Artificial intelligence (AI) applications also explode in smartphones, such as automatically tagging the photos, face detection and so on [Schroff et al., 2015; Hu et al., 2015]. Apple has been reported working on an “Apple Neural Engine” to partially move their AI processing module on device [Lumb et al., 2017]. If processing the users’ requests through sending them to the data center, there will be much overhead of the latency and power consumption caused by the commutation. As such, on-device AI processing is the future trend to balance power efficiency and latency. However, CNNs are known to have high computation complexity, which makes it hard to directly deploy on embedded devices. Therefore, compressed CNNs are in demand.
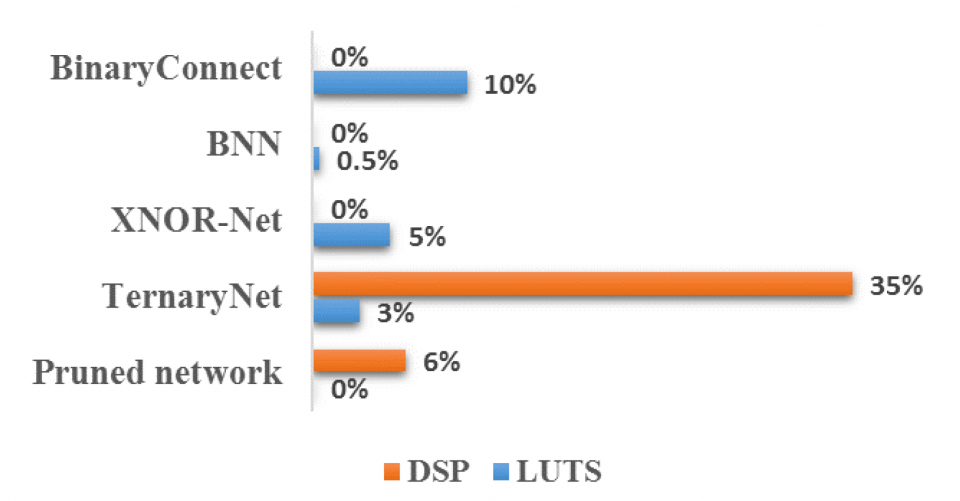
In the early stage, research work of hardware-friendly CNNs have focused on reducing the network precision down to 8-16 bits in the post-training stage [Suda et al., 2016], which either has a limited reduction or suffers from severer accuracy drop. Lately, in-training techniques have been brought up, achieving much higher compression ratio. BinaryConnect, BNN, TernaryNet and XNOR-Net [Courbariaux et al., 2015; Hubara et al., 2016; Rastegari et al., 2016; Zhu et al., 2016] have pushed to reduce the weight to binary or ternary (-1, 0, +1) values. Network pruning [Han et al., 2015] reduces the network size (the memory size for all the parameters) by means of reducing the number of connections. Regarding the network size, pruned network and TernaryNet can achieve 13x and 16x reduction [Zhu et al., 2016; Han et al., 2015], respectively. While BinaryConnect, BNN and XNOR-Net can achieve up to 32x reduction. In terms of computational complexity, only BNN and XNOR-Net with both binarized weights and activations can simply replace convolution operation with bitwise XNOR and bit count operation. However, XNOR-Net has additional scaling factor filters in each layer, which brings overhead to both memory and computation cost. From the above, BNN is the optimal solution for hardware deployment when considering both network size and computational complexity. In addition, BNN has drawn a lot of attention in hardware community [Li et al., 2017]. However, no existing study has explored scaling down BNN for a more efficient inference stage.
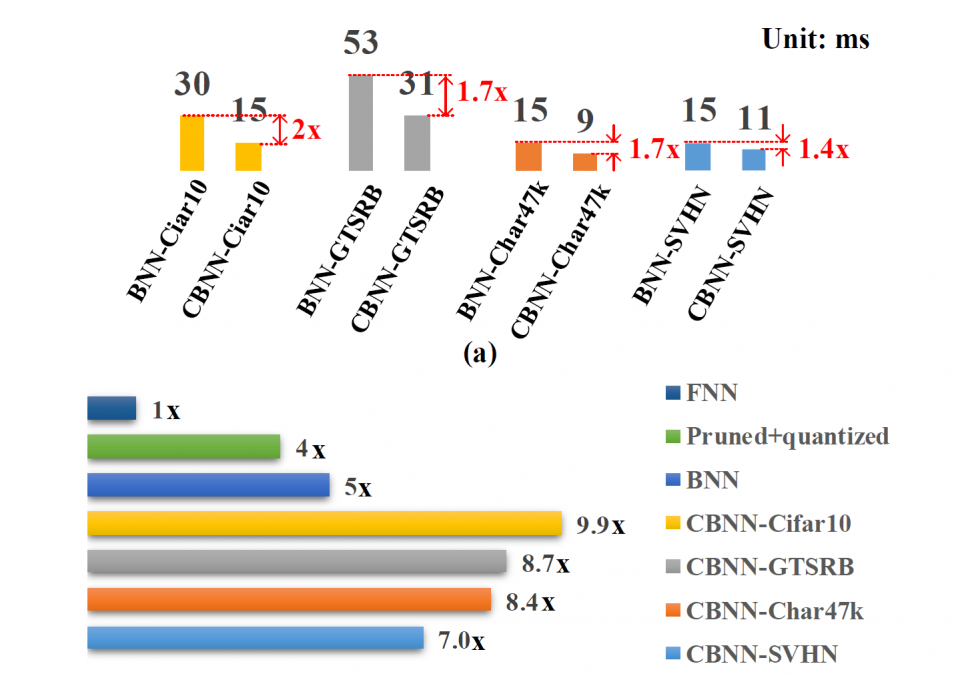
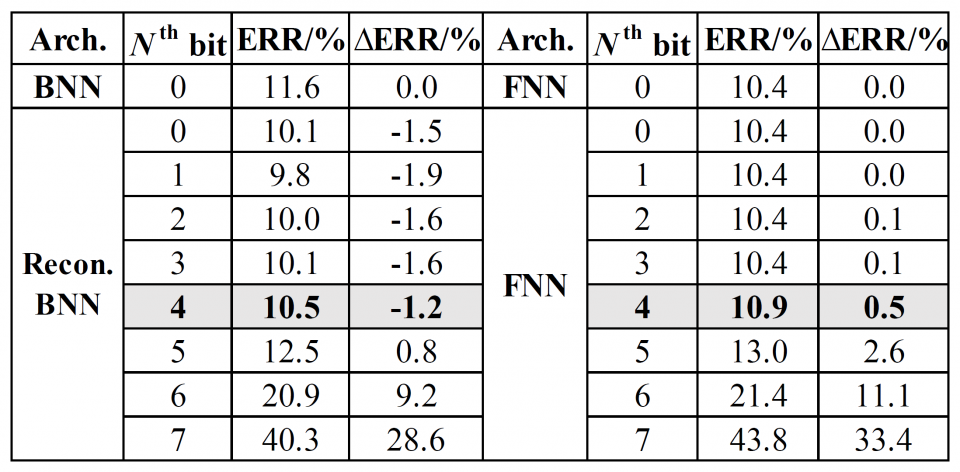
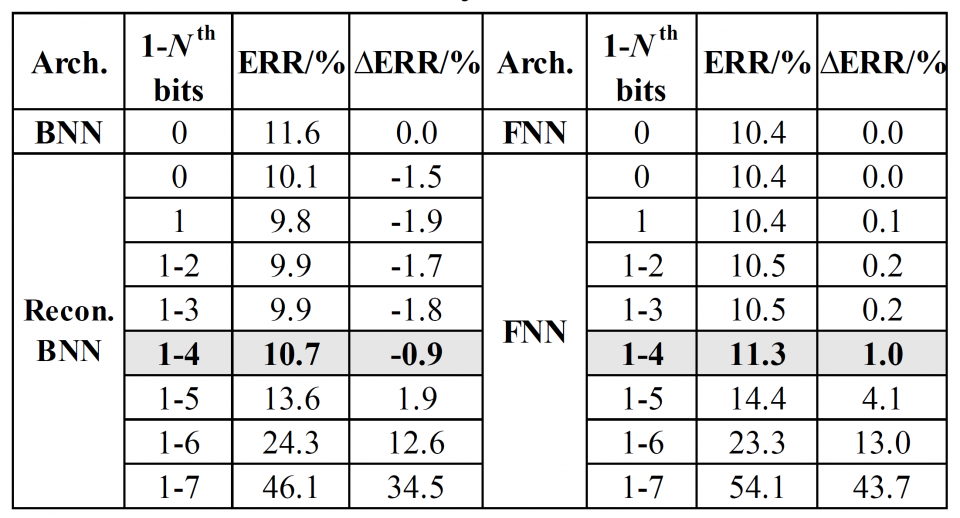
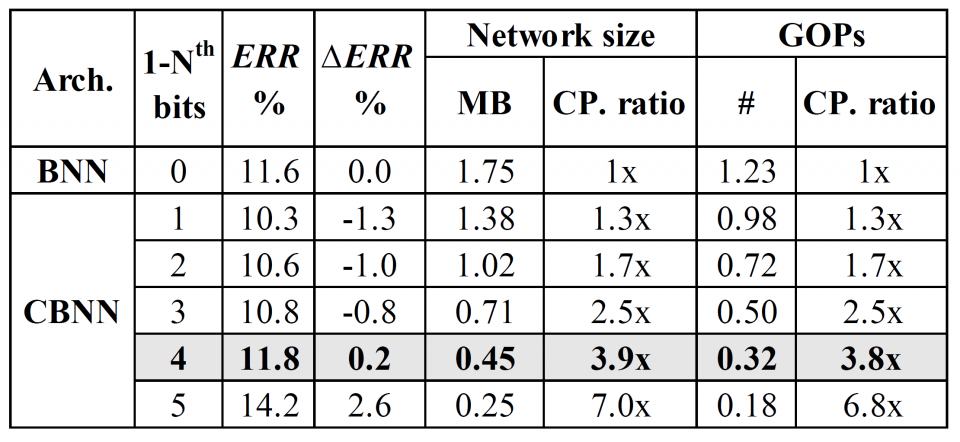
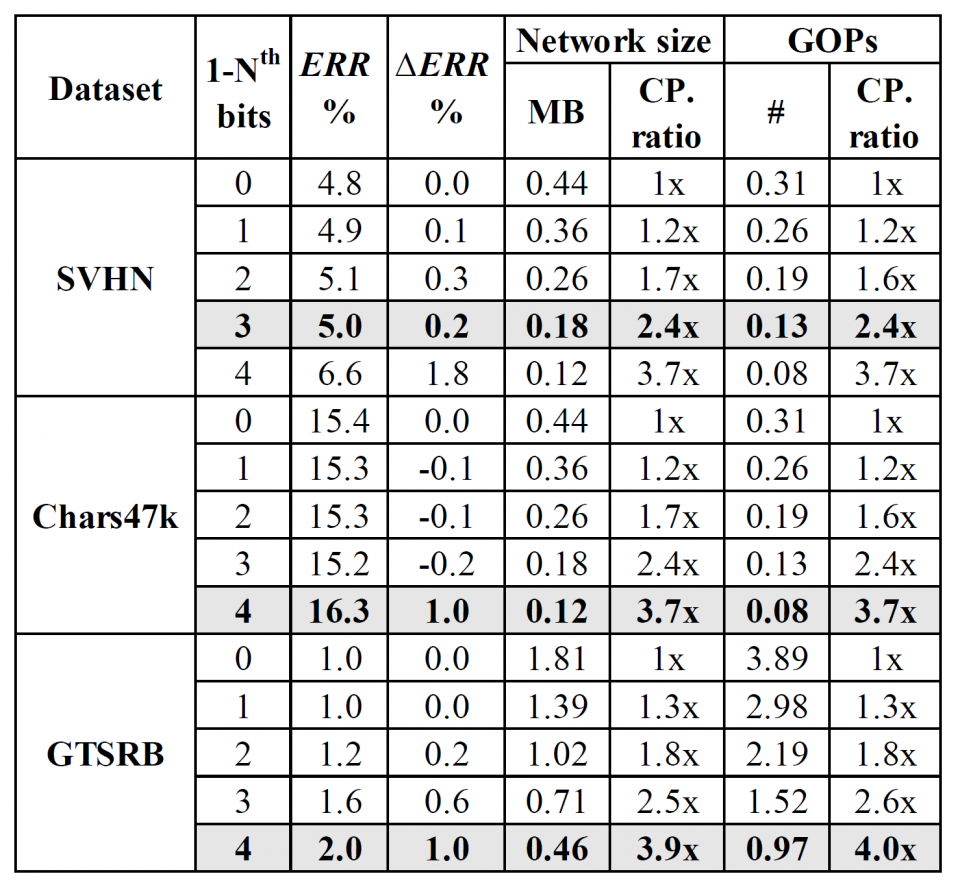
This work is the first one that explores and proves that there is still redundancy in BNN. The proposed flow to reduce the network size is triggered by conversion and analysis of input data rather than the network body, which is rarely seen in previous work. A novel flow is proposed to prune out the redundant input bit slices and rebuild a compact BNN through bit-level sensitivity analysis. Experiment results show that the compression ratio of the network size is achieving up to 3.9x with no more than 1% accuracy drop.
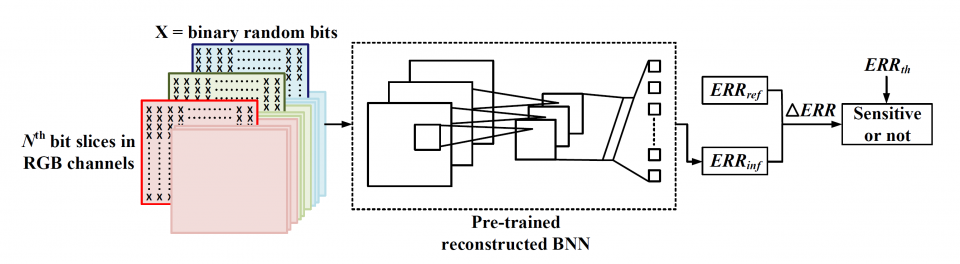
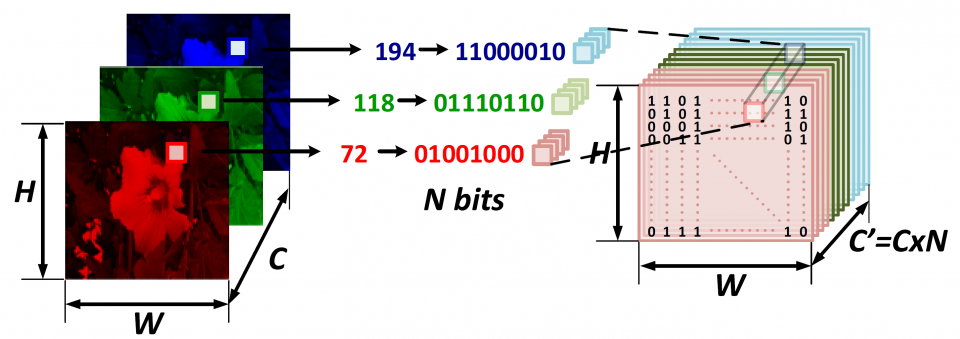
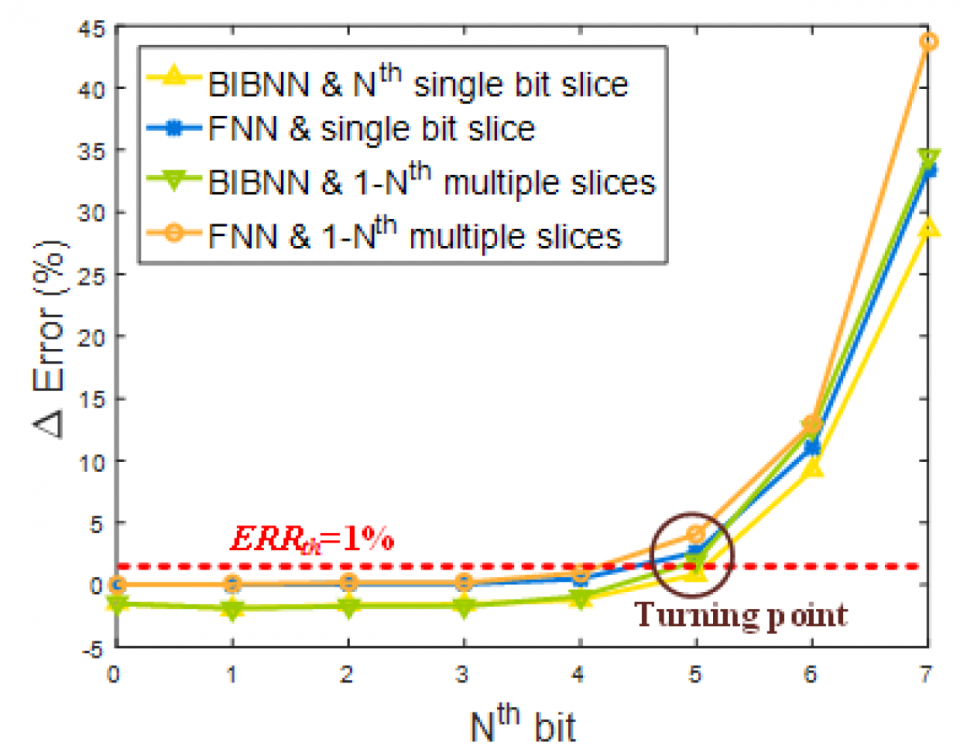

This work is supported by NSF grant IIS/CPS-1652038. The research infrastructure used by this work is supported by NSF grant CNS-1629888.
Copyright © 2015-2024 Parallel Systems and Computing Laboratory. All right reserved. | Site Admin: Fengbo Ren | Powered by Drupal.

