Sign In / Sign Out
Navigation for Entire University
The success of convolutional neural network (CNN) has resulted in a potential general machine learning engine for various computer vision applications (LeCun et al. 1998; Krizhevsky, Sutskever, and Hinton 2012), such as text detection, recognition and interpretation from images. Applications, such as Advanced Driver Assistance System (ADAS) for road signs with text, however, require a real-time processing capability that is beyond the existing approaches (Jaderberg et al. 2014; Jaderberg, Vedaldi, and Zisserman 2014) in terms of processing functionality, efficiency and latency.
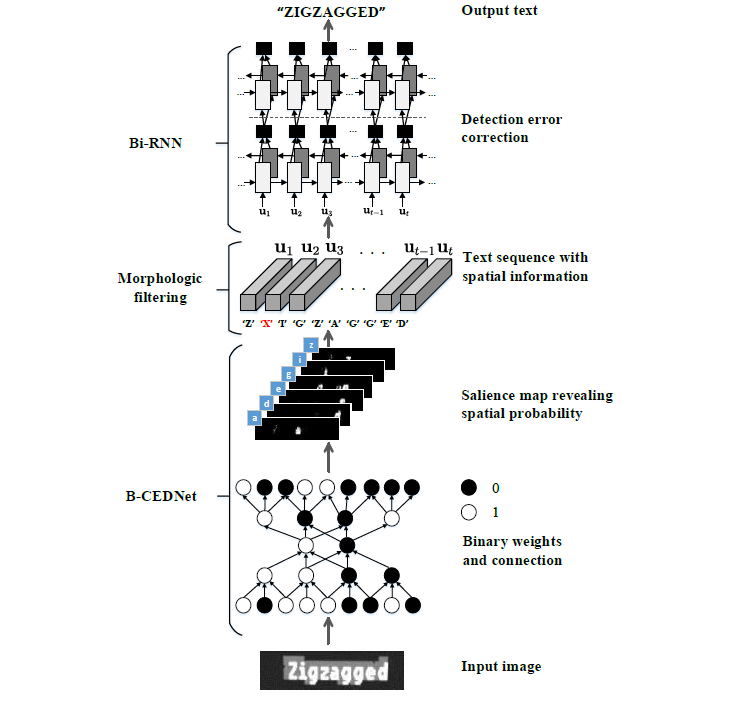
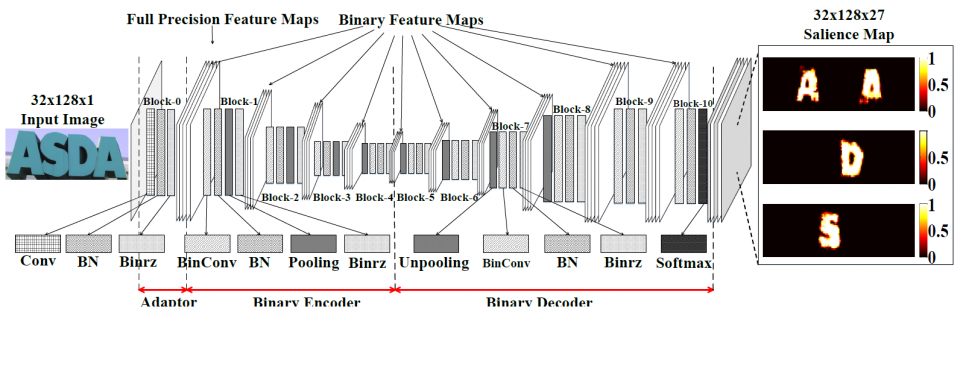
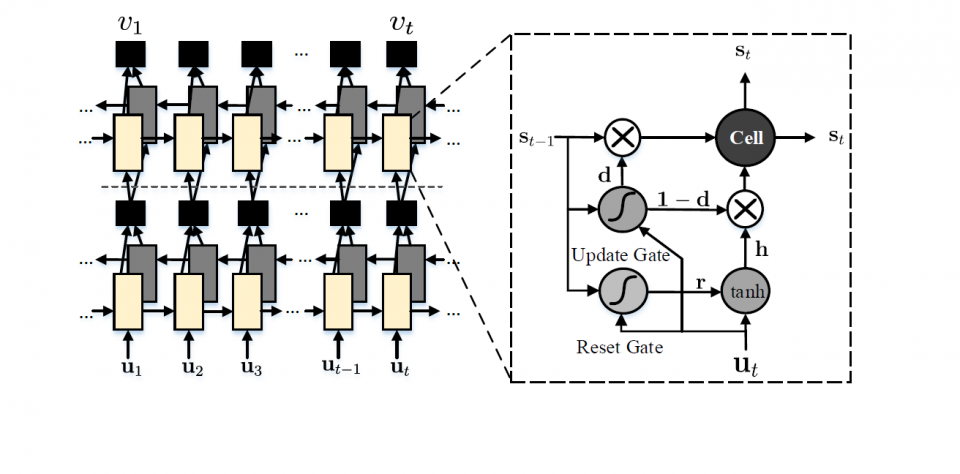
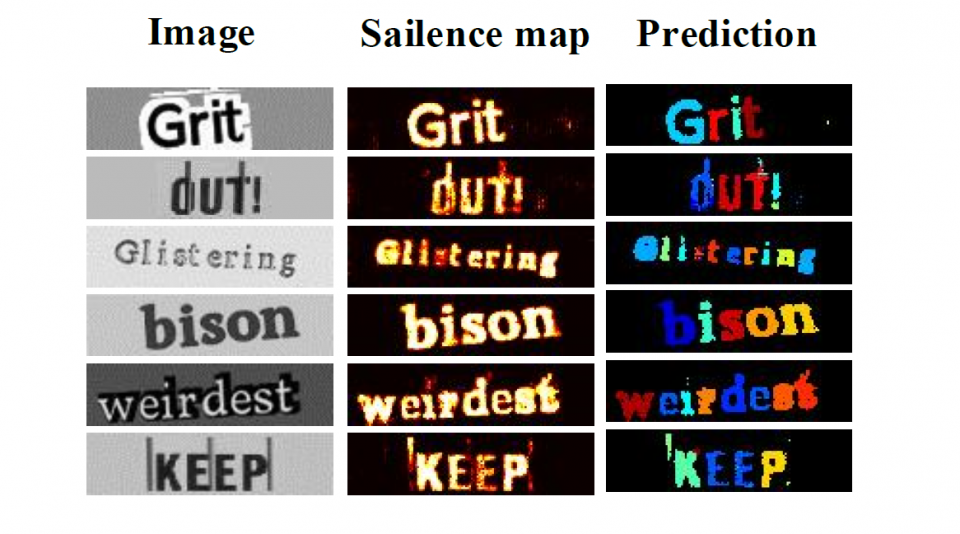
For a real-time scene text recognition application, one needs a method with memory efficiency and fast processing time. In this work, we reveal that binary features (Courbariaux and Bengio 2016) can effectively and efficiently represent the scene text image. Combining with deconvolution technique, we introduce a binary convolutional encoderdecoder network (B-CEDNet) for real-time one-shot character detection and recognition. The scene text recognition is further enhanced with a back-end character-level sequential correction and classification, based on a bidirectional recurrent neural network (Bi-RNN). Instead of detecting characters sequentially (Bissacco et al. 2013;Wang et al. 2012; Shi, Bai, and Yao 2015), our proposed method, called Squeezed- Text, can detect multiple characters simultaneously and extracts a length-variable character sequence with corresponding spatial information. This sequence will be subsequently fed into a Bi-RNN, which then learns the detection error characteristics from the previous stage to provides characterlevel correction and classification based on the spatial and contextual cues.
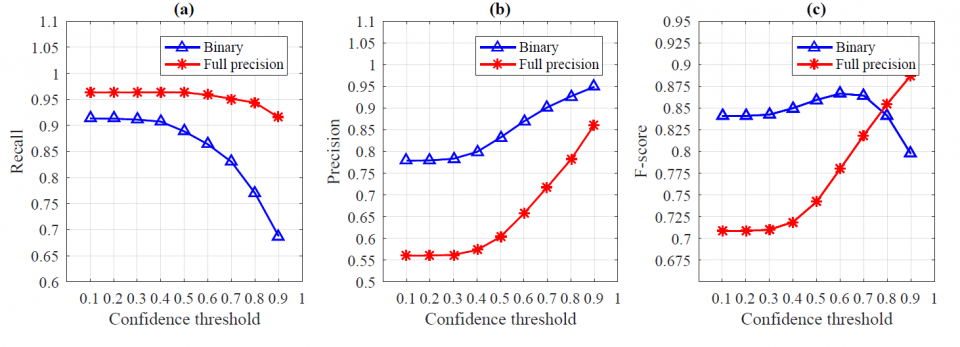
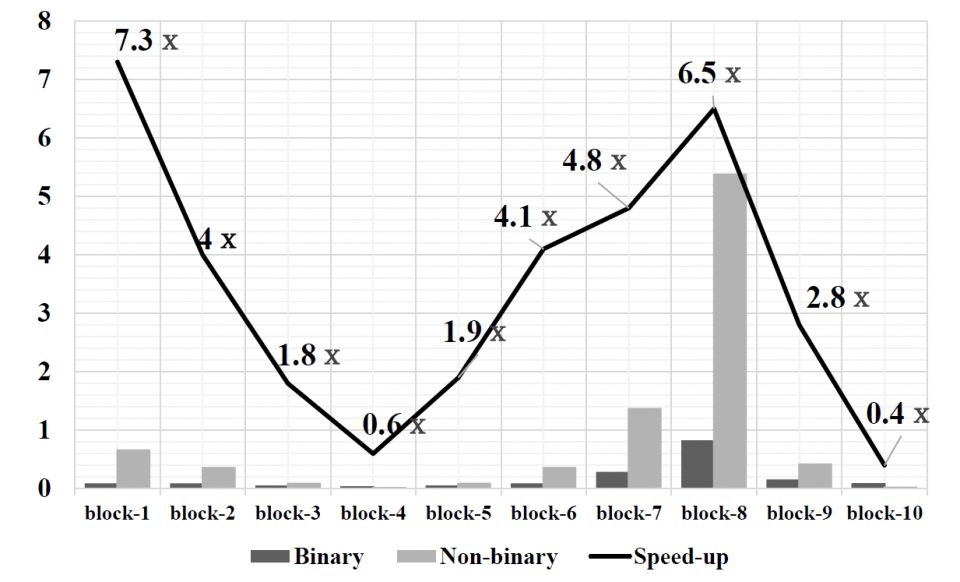
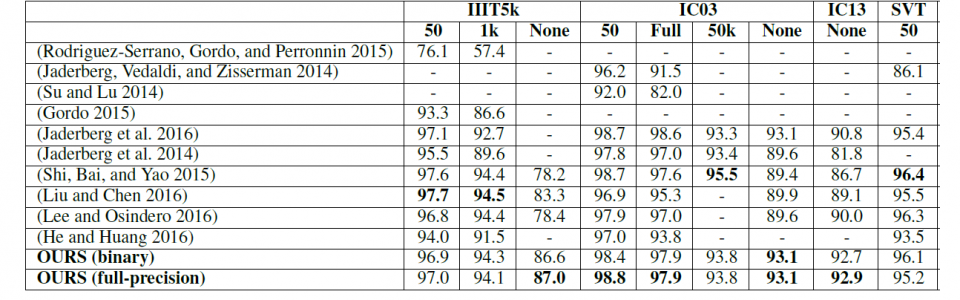
By training with over 1,000,000 synthetic scene text images, the proposed SqueezedText can achieve recall rate of 0.86, precision of 0.88 and F-score of 0.87 on ICDAR-03 (Lucas et al. 2003) dataset. More importantly, it achieves state-of-the-art accuracy of 93.8%, 92.7%, 94.3%96.1%and 83.6% on ICDAR-03, ICDAR-13, IIIT5K, STV and Synthe90K datasets. SqueezedText is realized on GPU with a small network size of 1.01 MB for B-CEDNet and 3.23 MB for Bi-RNN; and consumes less than 1 ms inference runtime on average. It is up to 4 faster and 6 smaller than state-of-the-art work.
The contributions of this work are summarized as follows:



Copyright © 2015-2024 Parallel Systems and Computing Laboratory. All right reserved. | Site Admin: Fengbo Ren | Powered by Drupal.

